{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"[](https://colab.research.google.com/github/neuromatch/climate-course-content/blob/main/tutorials/W2D4_ClimateResponse-Extremes&Variability/W2D4_Tutorial1.ipynb)  "
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Tutorial 1: Distributions\n",
"\n",
"**Week 2, Day 4, Extremes & Variability**\n",
"\n",
"**Content creators:** Matthias Aengenheyster, Joeri Reinders\n",
"\n",
"**Content reviewers:** Younkap Nina Duplex, Sloane Garelick, Zahra Khodakaramimaghsoud, Peter Ohue, Laura Paccini, Jenna Pearson, Agustina Pesce, Derick Temfack, Peizhen Yang, Cheng Zhang, Chi Zhang, Ohad Zivan\n",
"\n",
"**Content editors:** Paul Heubel, Jenna Pearson, Chi Zhang, Ohad Zivan\n",
"\n",
"**Production editors:** Wesley Banfield, Paul Heubel, Jenna Pearson, Konstantine Tsafatinos, Chi Zhang, Ohad Zivan\n",
"\n",
"**Our 2024 Sponsors:** CMIP, NFDI4Earth"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Tutorial Objectives"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"*Estimated timing of tutorial:* 30 minutes\n",
"\n",
"In this initial tutorial, your focus will be on examining the distribution of annual extreme precipitation levels in Germany. Your objective is to explore various aspects of the distribution, including the mean, variance, and skewness. By the end of this tutorial, you will be able to:\n",
"\n",
"- Visualize an observational record as both a time series and a distribution.\n",
"- Compute the *moments* of a record.\n",
"- Generate and plot a distribution with predefined *moments*."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Setup"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {},
"tags": []
},
"outputs": [],
"source": [
"# imports\n",
"import numpy as np\n",
"import matplotlib.pyplot as plt\n",
"import seaborn as sns\n",
"import pandas as pd\n",
"import os\n",
"import pooch\n",
"import tempfile\n",
"from scipy import stats"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Figure Settings\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Figure Settings\n",
"import ipywidgets as widgets # interactive display\n",
"\n",
"%config InlineBackend.figure_format = 'retina'\n",
"plt.style.use(\n",
" \"https://raw.githubusercontent.com/neuromatch/climate-course-content/main/cma.mplstyle\"\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Helper functions\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Helper functions\n",
"\n",
"\n",
"def pooch_load(filelocation=None, filename=None, processor=None):\n",
" shared_location = \"/home/jovyan/shared/Data/tutorials/W2D4_ClimateResponse-Extremes&Variability\" # this is different for each day\n",
" user_temp_cache = tempfile.gettempdir()\n",
"\n",
" if os.path.exists(os.path.join(shared_location, filename)):\n",
" file = os.path.join(shared_location, filename)\n",
" else:\n",
" file = pooch.retrieve(\n",
" filelocation,\n",
" known_hash=None,\n",
" fname=os.path.join(user_temp_cache, filename),\n",
" processor=processor,\n",
" )\n",
"\n",
" return file"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 1: Distributions\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 1: Distributions\n",
"\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'FGZ99bk2dBc'), ('Bilibili', 'BV1bj411Z739')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"pycharm": {
"name": "#%%\n"
},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @markdown\n",
"from ipywidgets import widgets\n",
"from IPython.display import IFrame\n",
"\n",
"link_id = \"6vu3z\"\n",
"\n",
"download_link = f\"https://osf.io/download/{link_id}/\"\n",
"render_link = f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/{link_id}/?direct%26mode=render%26action=download%26mode=render\"\n",
"# @markdown\n",
"out = widgets.Output()\n",
"with out:\n",
" print(f\"If you want to download the slides: {download_link}\")\n",
" display(IFrame(src=f\"{render_link}\", width=730, height=410))\n",
"display(out)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Section 1: Inspect a Precipitation Record and Plot it Over Time"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Extreme rainfall can pose flood hazards with disasterous consequences for society, the economy, and ecosystems. Annual maximum daily precipitation is a valuable measurement for assessing flood risks, and in this tutorial you will start the journey of statistically analyzing a dataset of annual maximum daily precipitation records for Germany. \n",
"\n",
"First, download the precipitation files:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {},
"tags": []
},
"outputs": [],
"source": [
"# download file: 'precipitationGermany_1920-2022.csv'\n",
"filename_precipitationGermany = \"precipitationGermany_1920-2022.csv\"\n",
"url_precipitationGermany = \"https://osf.io/xs7h6/download\"\n",
"data = pd.read_csv(\n",
" pooch_load(url_precipitationGermany, filename_precipitationGermany), index_col=0\n",
").set_index(\"years\")\n",
"data.columns = [\"precipitation\"]\n",
"precipitation = data.precipitation"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {},
"tags": []
},
"outputs": [],
"source": [
"precipitation"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"You can see that for each year between 1920 and 2022, there is one number. This represents the largest amount of precipitation that was observed at a point in Germany at 51 N 6 E. In other words, one looked at each day's precipitation for each year and included the highest amount in this time series. "
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Now we can plot a time series of the data from 1920-2022."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {},
"tags": []
},
"outputs": [],
"source": [
"precipitation.plot.line(style=\".-\",grid=True)\n",
"plt.xlabel(\"Time (years)\")\n",
"plt.ylabel(\"Annual Maximum Daily Precipitation \\n(mm/day)\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Tutorial 1: Distributions\n",
"\n",
"**Week 2, Day 4, Extremes & Variability**\n",
"\n",
"**Content creators:** Matthias Aengenheyster, Joeri Reinders\n",
"\n",
"**Content reviewers:** Younkap Nina Duplex, Sloane Garelick, Zahra Khodakaramimaghsoud, Peter Ohue, Laura Paccini, Jenna Pearson, Agustina Pesce, Derick Temfack, Peizhen Yang, Cheng Zhang, Chi Zhang, Ohad Zivan\n",
"\n",
"**Content editors:** Paul Heubel, Jenna Pearson, Chi Zhang, Ohad Zivan\n",
"\n",
"**Production editors:** Wesley Banfield, Paul Heubel, Jenna Pearson, Konstantine Tsafatinos, Chi Zhang, Ohad Zivan\n",
"\n",
"**Our 2024 Sponsors:** CMIP, NFDI4Earth"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Tutorial Objectives"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"*Estimated timing of tutorial:* 30 minutes\n",
"\n",
"In this initial tutorial, your focus will be on examining the distribution of annual extreme precipitation levels in Germany. Your objective is to explore various aspects of the distribution, including the mean, variance, and skewness. By the end of this tutorial, you will be able to:\n",
"\n",
"- Visualize an observational record as both a time series and a distribution.\n",
"- Compute the *moments* of a record.\n",
"- Generate and plot a distribution with predefined *moments*."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Setup"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {},
"tags": []
},
"outputs": [],
"source": [
"# imports\n",
"import numpy as np\n",
"import matplotlib.pyplot as plt\n",
"import seaborn as sns\n",
"import pandas as pd\n",
"import os\n",
"import pooch\n",
"import tempfile\n",
"from scipy import stats"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Figure Settings\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Figure Settings\n",
"import ipywidgets as widgets # interactive display\n",
"\n",
"%config InlineBackend.figure_format = 'retina'\n",
"plt.style.use(\n",
" \"https://raw.githubusercontent.com/neuromatch/climate-course-content/main/cma.mplstyle\"\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Helper functions\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"hide-input"
]
},
"outputs": [],
"source": [
"# @title Helper functions\n",
"\n",
"\n",
"def pooch_load(filelocation=None, filename=None, processor=None):\n",
" shared_location = \"/home/jovyan/shared/Data/tutorials/W2D4_ClimateResponse-Extremes&Variability\" # this is different for each day\n",
" user_temp_cache = tempfile.gettempdir()\n",
"\n",
" if os.path.exists(os.path.join(shared_location, filename)):\n",
" file = os.path.join(shared_location, filename)\n",
" else:\n",
" file = pooch.retrieve(\n",
" filelocation,\n",
" known_hash=None,\n",
" fname=os.path.join(user_temp_cache, filename),\n",
" processor=processor,\n",
" )\n",
"\n",
" return file"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Video 1: Distributions\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @title Video 1: Distributions\n",
"\n",
"from ipywidgets import widgets\n",
"from IPython.display import YouTubeVideo\n",
"from IPython.display import IFrame\n",
"from IPython.display import display\n",
"\n",
"\n",
"class PlayVideo(IFrame):\n",
" def __init__(self, id, source, page=1, width=400, height=300, **kwargs):\n",
" self.id = id\n",
" if source == 'Bilibili':\n",
" src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'\n",
" elif source == 'Osf':\n",
" src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'\n",
" super(PlayVideo, self).__init__(src, width, height, **kwargs)\n",
"\n",
"\n",
"def display_videos(video_ids, W=400, H=300, fs=1):\n",
" tab_contents = []\n",
" for i, video_id in enumerate(video_ids):\n",
" out = widgets.Output()\n",
" with out:\n",
" if video_ids[i][0] == 'Youtube':\n",
" video = YouTubeVideo(id=video_ids[i][1], width=W,\n",
" height=H, fs=fs, rel=0)\n",
" print(f'Video available at https://youtube.com/watch?v={video.id}')\n",
" else:\n",
" video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,\n",
" height=H, fs=fs, autoplay=False)\n",
" if video_ids[i][0] == 'Bilibili':\n",
" print(f'Video available at https://www.bilibili.com/video/{video.id}')\n",
" elif video_ids[i][0] == 'Osf':\n",
" print(f'Video available at https://osf.io/{video.id}')\n",
" display(video)\n",
" tab_contents.append(out)\n",
" return tab_contents\n",
"\n",
"\n",
"video_ids = [('Youtube', 'FGZ99bk2dBc'), ('Bilibili', 'BV1bj411Z739')]\n",
"tab_contents = display_videos(video_ids, W=730, H=410)\n",
"tabs = widgets.Tab()\n",
"tabs.children = tab_contents\n",
"for i in range(len(tab_contents)):\n",
" tabs.set_title(i, video_ids[i][0])\n",
"display(tabs)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"execution": {},
"pycharm": {
"name": "#%%\n"
},
"tags": [
"remove-input"
]
},
"outputs": [],
"source": [
"# @markdown\n",
"from ipywidgets import widgets\n",
"from IPython.display import IFrame\n",
"\n",
"link_id = \"6vu3z\"\n",
"\n",
"download_link = f\"https://osf.io/download/{link_id}/\"\n",
"render_link = f\"https://mfr.ca-1.osf.io/render?url=https://osf.io/{link_id}/?direct%26mode=render%26action=download%26mode=render\"\n",
"# @markdown\n",
"out = widgets.Output()\n",
"with out:\n",
" print(f\"If you want to download the slides: {download_link}\")\n",
" display(IFrame(src=f\"{render_link}\", width=730, height=410))\n",
"display(out)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Section 1: Inspect a Precipitation Record and Plot it Over Time"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Extreme rainfall can pose flood hazards with disasterous consequences for society, the economy, and ecosystems. Annual maximum daily precipitation is a valuable measurement for assessing flood risks, and in this tutorial you will start the journey of statistically analyzing a dataset of annual maximum daily precipitation records for Germany. \n",
"\n",
"First, download the precipitation files:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {},
"tags": []
},
"outputs": [],
"source": [
"# download file: 'precipitationGermany_1920-2022.csv'\n",
"filename_precipitationGermany = \"precipitationGermany_1920-2022.csv\"\n",
"url_precipitationGermany = \"https://osf.io/xs7h6/download\"\n",
"data = pd.read_csv(\n",
" pooch_load(url_precipitationGermany, filename_precipitationGermany), index_col=0\n",
").set_index(\"years\")\n",
"data.columns = [\"precipitation\"]\n",
"precipitation = data.precipitation"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {},
"tags": []
},
"outputs": [],
"source": [
"precipitation"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"You can see that for each year between 1920 and 2022, there is one number. This represents the largest amount of precipitation that was observed at a point in Germany at 51 N 6 E. In other words, one looked at each day's precipitation for each year and included the highest amount in this time series. "
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Now we can plot a time series of the data from 1920-2022."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {},
"tags": []
},
"outputs": [],
"source": [
"precipitation.plot.line(style=\".-\",grid=True)\n",
"plt.xlabel(\"Time (years)\")\n",
"plt.ylabel(\"Annual Maximum Daily Precipitation \\n(mm/day)\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"\n",
" Click here for a description of the plot
\n",
"A time series of the annual maximum daily precipitation in millimeters per day per year. The data ranges from approximately 16 mm/day in the 1920s to almost 70 mm/day around 1970. About four peaks show unusual events of extreme precipitation (in 1924, 1966, 1982 and 2021). Moreover, a positive trend over time seems to be visible. \n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"To make this dataset more interpretable, we can plot a histogram of the data. Recall that we can make a histogram of this data by plotting the y-axis from the previous figure on the x-axis of this new figure versus the count of how many data points fall within a 'bin' on the x-axis. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {},
"tags": []
},
"outputs": [],
"source": [
"# create the bins (x axis) for the data\n",
"fig, ax = plt.subplots()\n",
"bins = np.arange(0, precipitation.max(), 2)\n",
"\n",
"# make the histogram\n",
"sns.histplot(precipitation, bins=bins, ax=ax)\n",
"\n",
"# set limits and labels\n",
"ax.set_xlim(bins[0], bins[-1])\n",
"ax.set_xlabel(\"Annual Maximum Daily Precipitation \\n(mm/day)\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"\n",
" Click here for a description of the plot
\n",
"Histogram plot of the annual maximum daily precipitation in millimeters per day. The horizontal axis of the histogram represents the data's range via bins, while the vertical axis represents the frequency of occurrences within each interval by counting the number of data points that fall into each bin. \n",
"By visually inspecting the histogram we get an impression of the shape, central tendency, and spread of the dataset. \n",
"The bin with the largest amount of occurrences shows 12 counts of annual maximum daily precipitation between 14 and 16 millimeters per day. \n",
"Bins that show at least one count range from 14 millimeters per day to 60 millimeters per day. \n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Next let's calculate the moments of our dataset. A [moment](https://glossary.ametsoc.org/wiki/Moment) helps us define the center of mass ([mean](https://glossary.ametsoc.org/wiki/Expected_value)), scale ([variance](https://glossary.ametsoc.org/wiki/Variance)), and shape ([skewness](https://glossary.ametsoc.org/wiki/Skewness) and [kurtosis](https://glossary.ametsoc.org/wiki/Kurtosis)) of a distribution. The scale is how the data is stretched or compressed along the x-axis, while the shape parameters help us answer questions about the geometry of the distribution, for example if data points lie more frequently to one side of the mean than the other or if the tails are 'heavy' (i.e. larger chance of getting extreme values).\n",
"\n",
"Let's compute the mean, the variance and the [standard deviation](https://glossary.ametsoc.org/wiki/Standard_deviation) of your precipitation data. Plot the mean as a vertical line on the histogram."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {},
"tags": []
},
"outputs": [],
"source": [
"# mean\n",
"mean_pr = precipitation.mean()\n",
"\n",
"# variance\n",
"var_pr = precipitation.var()\n",
"\n",
"# standard deviation\n",
"std_pr = precipitation.std()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {},
"tags": []
},
"outputs": [],
"source": [
"mean_pr, var_pr, std_pr"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {},
"tags": []
},
"outputs": [],
"source": [
"# re-plot histogram from above\n",
"fig, ax = plt.subplots()\n",
"bins = np.arange(0, precipitation.max(), 2)\n",
"sns.histplot(precipitation, bins=bins, ax=ax) # this will plot the counts for each bin\n",
"ax.set_xlim(bins[0], bins[-1])\n",
"\n",
"ylim = ax.get_ylim()\n",
"\n",
"# add in vertical line at mean\n",
"ax.vlines(mean_pr, ymin=ylim[0], ymax=ylim[1], color=\"C3\", lw=3, label=\"mean\")\n",
"ax.set_xlabel(\"Annual Maximum Daily Precipitation \\n(mm/day)\")\n",
"ax.legend()"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"\n",
" Click here for a description of the plot
\n",
"Histogram plot of the annual maximum daily precipitation in millimeters per day as above. Here, the computed mean is highlighted as a red vertical line. The mean is shown in the 30 to 32 bin as the calculated value is approximately 30.97 millimeters per day.\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"As you can observe, the range of values on either side of the mean-line you added earlier is unequal, suggesting a skewed distribution. To assess the extent of the potential [skewness](https://glossary.ametsoc.org/wiki/Skewness), we will use the [`.skew()`](https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.skew.html#pandas-dataframe-skew) function. We will also generate a set of 100 random values from a normal distribution (mean = 0, standard deviation = 1) and compare its skewness to that of the precipitation data."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {},
"tags": []
},
"outputs": [],
"source": [
"# calculate the skewness of our precipitation data\n",
"precipitation.skew()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {},
"tags": []
},
"outputs": [],
"source": [
"# generate data following a normal distribution (mean = 0, standard deviation = 1)\n",
"normal_data = np.random.normal(0, 1, size=data.index.size)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {},
"tags": []
},
"outputs": [],
"source": [
"# calculate the skewness of a normal distribution\n",
"stats.skew(normal_data)"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Note that a more positive value of skewness means the tail on the right is longer/heavier and extends more towards the positive values, and vice versa for a more negative skewness. An unskewed dataset would have a value of zero - such as the normal distribution.\n",
"\n",
"By comparing the precipitation data to the skewness of the normal distribution, we can see that our data is positively skewed, meaning that the right tail of the distribution contains more data than the left. This is consistent with our findings from the histogram.\n",
"\n",
"To delve deeper into this observation, let's try fitting a normal distribution to our precipitation data. This entails computing the mean and standard deviation of the 'precipitation' variable, which serve as the two parameters for a normal distribution. \n",
"\n",
"By utilizing the `scipy` function `norm.pdf`, we can generate a probability density function (pdf) that accompanies our histogram. The pdf provides insight into the probability of encountering various levels of precipitation based on the available data. For a normal distribution the mean value exhibits the highest probability (this is not the case for all distributions!)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {},
"tags": []
},
"outputs": [],
"source": [
"fig, ax = plt.subplots()\n",
"bins = np.arange(0, precipitation.max(), 2)\n",
"sns.histplot(\n",
" precipitation, bins=bins, ax=ax, stat=\"density\"\n",
") # notice the different stat being ploted\n",
"ax.set_xlim(bins[0], bins[-1])\n",
"\n",
"ylim = ax.get_ylim()\n",
"\n",
"# add in vertical line at mean\n",
"ax.vlines(mean_pr, ymin=ylim[0], ymax=ylim[1], color=\"C3\", lw=3, label=\"mean\")\n",
"\n",
"# add PDF\n",
"x_r100 = np.arange(0, 100, 1)\n",
"ax.plot(x_r100, stats.norm.pdf(x_r100, mean_pr, std_pr), c=\"k\", lw=3)\n",
"\n",
"ax.set_xlabel(\"Annual Maximum Daily Precipitation \\n(mm/day)\")\n",
"ax.legend()"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"\n",
" Click here for a description of the plot
\n",
"Histogram plot of the annual maximum daily precipitation in millimeters per day as above. Here, the computed mean is highlighted as a red vertical line. Furthermore, the computed probability density function is overlaid in black.\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Coding Exercises 1\n",
"\n",
"Add uncertainty bands to the distribution.\n",
"\n",
"1. Create 1000 records of 100 samples each that are drawn from a normal distribution with the mean and standard deviation of the precipitation record.\n",
"2. Compute the 5-th and 95-th percentiles across the 1000-member ensemble and add them to the figure above to get an idea of the uncertainty."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"Hint: you can use the function `np.random.normal()` to draw from a normal distribution. Call `np.random.normal()` or `help(np.random.normal)` to understand how to use it. `np.quantile()` is useful for computing quantiles. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {},
"tags": []
},
"outputs": [],
"source": [
"# take 1000 records of 100 samples\n",
"random_samples = ...\n",
"\n",
"# create placeholder for pdfs\n",
"pdfs = np.zeros([x_r100.size, 1000])\n",
"\n",
"# loop through all 1000 records and create a pdf of each sample\n",
"for i in range(1000):\n",
" # find pdfs\n",
" pdfi = ...\n",
"\n",
" # add to array\n",
" ..."
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {},
"tags": []
},
"source": [
"[*Click for solution*](https://github.com/neuromatch/climate-course-content/tree/main/tutorials/W2D4_ClimateResponse-Extremes&Variability/solutions/W2D4_Tutorial1_Solution_a8307b5a.py)\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"execution": {}
},
"outputs": [],
"source": [
"fig, ax = plt.subplots()\n",
"\n",
"# make histogram\n",
"_ = ...\n",
"\n",
"# set x limits\n",
"_ = ...\n",
"\n",
"# get y lims for plotting mean line\n",
"ylim = ...\n",
"\n",
"# add vertical line with mean\n",
"_ = ...\n",
"\n",
"# plot pdf\n",
"_ = ...\n",
"\n",
"# plot 95th percentile\n",
"_ = ...\n",
"\n",
"# plot 5th percentile\n",
"_ = ...\n",
"\n",
"# set xlabel\n",
"ax.set_xlabel(\"Annual Maximum Daily Precipitation \\n(mm/day)\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {},
"tags": []
},
"source": [
"[*Click for solution*](https://github.com/neuromatch/climate-course-content/tree/main/tutorials/W2D4_ClimateResponse-Extremes&Variability/solutions/W2D4_Tutorial1_Solution_e35d1bc8.py)\n",
"\n",
"*Example output:*\n",
"\n",
"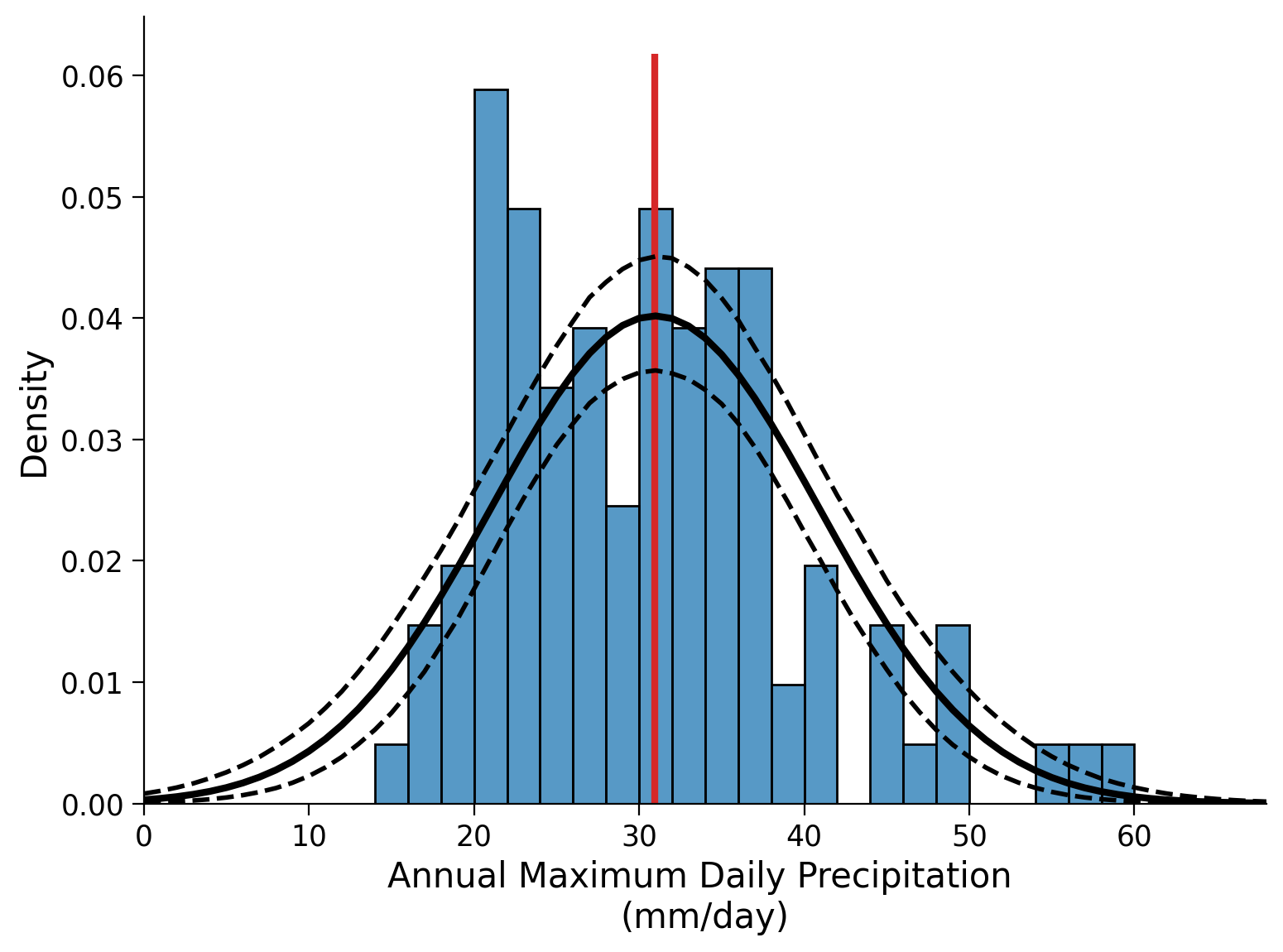 \n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"
\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"\n",
" Click to see description of plot
\n",
"Histogram plot of the annual maximum daily precipitation in millimeters per day. Here, the computed mean is highlighted as a red vertical line. The computed probability density function is overlaid in black as above. Furthermore, the 5th and 95th percentiles across the 1000-member ensemble are computed and added to the figure as dashed black lines to get an idea of the uncertainty.\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"## Questions 1\n",
"1. Based on the current plot, does a normal distribution accurately describe your model? Why or why not? "
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"execution": {}
},
"source": [
"[*Click for solution*](https://github.com/neuromatch/climate-course-content/tree/main/tutorials/W2D4_ClimateResponse-Extremes&Variability/solutions/W2D4_Tutorial1_Solution_a3bcafac.py)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Summary\n",
"In this tutorial, you focused on the analysis of the annual maximum daily precipitation levels in Germany. You started by visualizing the observational record as both a time series and a distribution. This led you to compute the moments of the record, specifically, the mean, variance, and standard deviation. You then compared the skewness of the precipitation data to a normally distributed set of values. Finally, you assessed the fit of a normal distribution to your dataset."
]
},
{
"cell_type": "markdown",
"metadata": {
"execution": {}
},
"source": [
"# Resources\n",
"\n",
"Data from this tutorial uses the 0.25 degree precipitation dataset E-OBS. It combines precipitation observations to generate a gridded (i.e. no \"holes\") precipitation over Europe. We used the precipitation data from the gridpoint at 51°N, 6°E. \n",
"\n",
"The dataset can be accessed using the KNMI Climate Explorer [here](https://climexp.knmi.nl/select.cgi?id=someone@somewhere&field=ensembles_025_rr). The Climate Explorer is a great resource to access, manipulate and visualize climate data, including observations and climate model simulations. It is freely accessible - feel free to explore!"
]
}
],
"metadata": {
"colab": {
"collapsed_sections": [],
"include_colab_link": true,
"name": "W2D4_Tutorial1",
"provenance": [],
"toc_visible": true
},
"kernel": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.9.19"
}
},
"nbformat": 4,
"nbformat_minor": 4
}