![]()

Tutorial 4: Synthesising & Interpreting Diverse Data Sources#
Week 2, Day 1, An Ensemble of Futures
Content creators: Brodie Pearson, Julius Busecke, Tom Nicholas
Content reviewers: Mujeeb Abdulfatai, Nkongho Ayuketang Arreyndip, Jeffrey N. A. Aryee, Younkap Nina Duplex, Sloane Garelick, Paul Heubel, Zahra Khodakaramimaghsoud, Peter Ohue, Jenna Pearson, Abel Shibu, Derick Temfack, Peizhen Yang, Cheng Zhang, Chi Zhang, Ohad Zivan
Content editors: Paul Heubel, Jenna Pearson, Ohad Zivan, Chi Zhang
Production editors: Wesley Banfield, Paul Heubel, Jenna Pearson, Konstantine Tsafatinos, Chi Zhang, Ohad Zivan
Our 2024 Sponsors: CMIP, NFDI4Earth
Tutorial Objectives#
Estimated timing for tutorial: 40 minutes
In this tutorial, we will synthesize scientific knowledge from various sources and use this diverse information to validate and contextualize CMIP6 simulations. By the end of this tutorial, you will be able to
Create a time series of global mean sea surface temperature from observations, models, and proxy data;
Use this data to validate and contextualize climate models, as well as to provide a holistic picture of Earth’s past and future climate evolution.
Setup#
# installations ( uncomment and run this cell ONLY when using google colab or kaggle )
# !pip install condacolab &> /dev/null
# import condacolab
# condacolab.install()
# # Install all packages in one call (+ use mamba instead of conda), this must in one line or code will fail
# !mamba install xarray-datatree intake-esm gcsfs xmip aiohttp nc-time-axis cf_xarray xarrayutils &> /dev/null
# imports
import intake
import numpy as np
import matplotlib.pyplot as plt
import xarray as xr
from xmip.preprocessing import combined_preprocessing
from xmip.postprocessing import _parse_metric
from datatree import DataTree
/opt/hostedtoolcache/Python/3.9.19/x64/lib/python3.9/site-packages/esmpy/interface/loadESMF.py:92: VersionWarning: ESMF installation version 8.7.0 beta snapshot, ESMPy version 8.7.0b7
warnings.warn("ESMF installation version {}, ESMPy version {}".format(
Figure settings#
Show code cell source
# @title Figure settings
import ipywidgets as widgets # interactive display
plt.style.use(
"https://raw.githubusercontent.com/neuromatch/climate-course-content/main/cma.mplstyle"
)
%matplotlib inline
Helper functions#
Show code cell source
# @title Helper functions
def global_mean(ds: xr.Dataset) -> xr.Dataset:
"""Global average, weighted by the cell area"""
return ds.weighted(ds.areacello.fillna(0)).mean(["x", "y"], keep_attrs=True)
# calculate anomaly to reference period
def datatree_anomaly(dt):
dt_out = DataTree()
for model, subtree in dt.items():
# for the coding exercise, ellipses will go after sel on the following line
ref = dt[model]["historical"].ds.sel(time=slice("1950", "1980")).mean()
dt_out[model] = subtree - ref
return dt_out
def plot_historical_ssp126_combined(dt):
for model in dt.keys():
datasets = []
for experiment in ["historical", "ssp126"]:
datasets.append(dt[model][experiment].ds.tos)
da_combined = xr.concat(datasets, dim="time")
Section 1: Reproduce Global Mean SST for Historical and Future Scenario Experiments#
We are now going to reproduce the plot you created in Tutorial 3, which showed the likely range of CMIP6 simulated global mean sea surface temperature for historical and future scenarios (SSP1-2.6 and SSP5-8.5) experiments from a multi-model ensemble. However, now we will add an additional dataset called HadISST which is an observational dataset spanning back to the year 1870. Later in the tutorial, we will also include the paleo data you saw in the previous mini-lecture.
Section 1.1: Load CMIP6 SST Data from Several Models using xarray#
Let’s load the five different CMIP6 models again for the three CMIP6 experiments.
col = intake.open_esm_datastore(
"https://storage.googleapis.com/cmip6/pangeo-cmip6.json"
) # open an intake catalog containing the Pangeo CMIP cloud data
# pick our five example models
# there are many more to test out! Try executing `col.df['source_id'].unique()` to get a list of all available models
source_ids = ["IPSL-CM6A-LR", "GFDL-ESM4", "ACCESS-CM2", "MPI-ESM1-2-LR", "TaiESM1"]
experiment_ids = ["historical", "ssp126", "ssp585"]
# from the full `col` object, create a subset using facet search
cat = col.search(
source_id=source_ids,
variable_id="tos",
member_id="r1i1p1f1",
table_id="Omon",
grid_label="gn",
experiment_id=experiment_ids,
require_all_on=[
"source_id"
], # make sure that we only get models which have all of the above experiments
)
# convert the sub-catalog into a datatree object, by opening each dataset into an xarray.Dataset (without loading the data)
kwargs = dict(
preprocess=combined_preprocessing, # apply xMIP fixes to each dataset
xarray_open_kwargs=dict(
use_cftime=True
), # ensure all datasets use the same time index
storage_options={
"token": "anon"
}, # anonymous/public authentication to google cloud storage
)
cat.esmcat.aggregation_control.groupby_attrs = ["source_id", "experiment_id"]
dt = cat.to_datatree(**kwargs)
cat_area = col.search(
source_id=source_ids,
variable_id="areacello", # for the coding exercise, ellipses will go after the equals on this line
member_id="r1i1p1f1",
table_id="Ofx", # for the coding exercise, ellipses will go after the equals on this line
grid_label="gn",
experiment_id=[
"historical"
], # for the coding exercise, ellipses will go after the equals on this line
require_all_on=["source_id"],
)
cat_area.esmcat.aggregation_control.groupby_attrs = ["source_id", "experiment_id"]
dt_area = cat_area.to_datatree(**kwargs)
dt_with_area = DataTree()
for model, subtree in dt.items():
metric = dt_area[model]["historical"].ds["areacello"]
dt_with_area[model] = subtree.map_over_subtree(_parse_metric, metric)
# average every dataset in the tree globally
dt_gm = dt_with_area.map_over_subtree(global_mean)
dt_gm_anomaly = datatree_anomaly(dt_gm)
--> The keys in the returned dictionary of datasets are constructed as follows:
'source_id/experiment_id'
--> The keys in the returned dictionary of datasets are constructed as follows:
'source_id/experiment_id'
Coding Exercise 1.1#
Complete the following code to:
Calculate a time series of the global mean sea surface temperature (GMSST) from the HadISST dataset
Subtract a base period from the HadISST GMSST time series. Use the same base period as the CMIP6 time series you are comparing against.
#################################################
## TODO for students: Add HadISST (observation-based) dataset to the previous CMIP ensemble plot. ##
# Please remove the following line of code once you have completed the exercise:
raise NotImplementedError("Student exercise: Add HadISST (observation-based) dataset to the previous CMIP ensemble plot.")
#################################################
fig, ax = plt.subplots()
for experiment, color in zip(["historical", "ssp126", "ssp585"], ["C0", "C1", "C2"]):
datasets = []
for model in dt_gm_anomaly.keys():
# calculate annual mean
annual_sst = (
dt_gm_anomaly[model][experiment]
.ds.tos.coarsen(time=12)
.mean()
.assign_coords(source_id=model)
.load()
)
datasets.append(
annual_sst.sel(time=slice(None, "2100")).load()
) # the french model has a long running member for ssp 126
# concatenate all along source_id dimension
da = xr.concat(datasets, dim="source_id", join="override").squeeze()
# compute ensemble mean and draw time series
da.mean("source_id").plot(color=color, label=experiment, ax=ax)
# extract time coordinates
x = da.time.data
# calculate the lower and upper bound of the likely range
da_lower = da.squeeze().quantile(0.17, dim="source_id")
da_upper = da.squeeze().quantile(0.83, dim="source_id")
# shade via quantile boundaries
ax.fill_between(x, da_lower, da_upper, alpha=0.5, color=color)
# but now add observations (https://pangeo-forge.org/dashboard/feedstock/43)
store = "https://ncsa.osn.xsede.org/Pangeo/pangeo-forge/HadISST-feedstock/hadisst.zarr"
ds_obs = xr.open_dataset(store, engine="zarr", chunks={}).convert_calendar(
"standard", use_cftime=True
)
# mask missing values
ds_obs = ds_obs.where(ds_obs > -1000)
weights = np.cos(
np.deg2rad(ds_obs.latitude)
) # In a regular lon/lat grid, area is ~cos(latitude)
# calculate weighted global mean for observations
sst_obs_gm = ...
# calculate anomaly for observations
sst_obs_gm_anomaly = ...
sst_obs_gm_anomaly.coarsen(time=12, boundary="trim").mean().plot(
color="0.3", label="Observations", ax=ax
)
ax.set_ylabel("Global Mean SST with respect to 1950-1980 (°C)")
ax.set_xlabel("Time (years)")
ax.legend()
Example output:
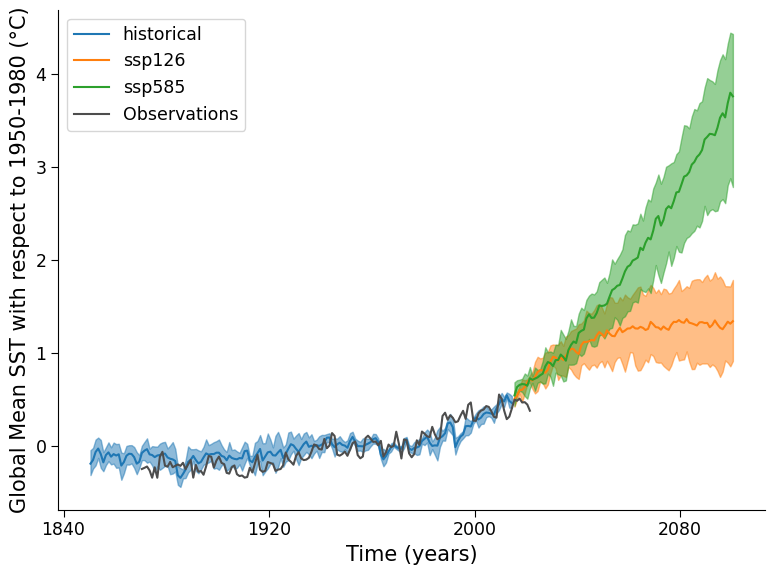
Questions 1.1 Climate Connection#
Now that you have a modern and projected time series containing models and observations,
What context and/or validation of the simulations does this information provide?
What additional context/validation can you glean by also considering the paleo proxy information in the figure below? (This figure was shown in the last video)
Note the paleo periods on this figure represent the Mid-Pleiocene Warm Period (MPWP), the Last Inter-glacial (LIG) and the Last Glacial Maximum (LGM)

This image shows a part of panel a) from Figure 9.3 from the IPCC AR6 WG1 report. This figure has the following caption: Figure 9.3 | Sea surface temperature (SST) and its changes with time. (a) Time series of global mean SST anomaly relative to 1950–1980 climatology. Shown are paleoclimate reconstructions and PMIP models, observational reanalyses (HadISST) and multi-model means from the Coupled Model Intercomparison Project (CMIP) historical simulations, CMIP projections, and HighResMIP experiment.
[(b) Map of observed SST (1995–2014 climatology HadISST). (c) Historical SST changes from observations. (d) CMIP 2005–2100 SST change rate. (e) Bias of CMIP. (f) CMIP change rate. (g) 2005–2050 change rate for SSP5-8.5 for the CMIP ensemble. (h) Bias of HighResMIP (bottom left) over 1995–2014. (i) HighResMIP change rate for 1950–2014. (j) 2005–2050 change rate for SSP5-8.5 for the HighResMIP ensemble. No overlay indicates regions with high model agreement, where ≥80% of models agree on sign of change. Diagonal lines indicate regions with low model agreement, where <80% of models agree on sign of change (see Cross-Chapter Box Atlas.1 for more information). Further details on data sources and processing are available in the chapter data table (Table 9.SM.9).]
Summary#
In the final tutorial of the day, we learned about the importance of synthesizing CMIP6 model data (future projections and historical simulations), alongside modern climate and palroclimate observations. This synthesis provides validation of CMIP6 simulation data, and it provides historical context for recent and projected rapid changes in Earth’s climate, as many of these changes are unprecedented in human-recored history.
In the upcoming tutorials, we will shift our focus towards the socio-economic aspects of future climate change. This exploration will take various forms, including the design of the Shared Socioeconomic Pathways (SSPs) we began using today. We’ll contemplate the realism of different socio-economic future scenarios and examine their potential impacts on future climate forcings. Moreover, we’ll delve into how a changing climate might affect society. As we proceed with the next tutorials, keep in mind the intricate connection between physical and socio-economic changes.
Resources#
This tutorial uses data from the simulations conducted as part of the CMIP6 multi-model ensemble.
For examples on how to access and analyze data, please visit the Pangeo Cloud CMIP6 Gallery
For more information on what CMIP is and how to access the data, please see this page.
Please find the full IPCC AR6 WG1 report and various supplementary materials here.