![]()

Arctic Sea Ice Change#
Content creators: Alistair Duffey, Will Gregory, Michel Tsamados
Content reviewers: Paul Heubel, Laura Paccini, Jenna Pearson, Ohad Zivan
Content editors: Paul Heubel
Production editors: Paul Heubel, Konstantine Tsafatinos
Our 2024 Sponsors: CMIP, NFDI4Earth
# @title Project Background
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'gt6o3lqu5zA'), ('Bilibili', 'BV12pGDeVEBw'), ('Osf', '<video_id_3>')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)
# @title Slides
# @markdown These are the slides for the video introduction to the project
from IPython.display import IFrame
link_id = "y6em2"
print(f"If you want to download the slides: https://osf.io/download/{link_id}/")
IFrame(src=f"https://mfr.ca-1.osf.io/render?url=https://osf.io/{link_id}/?direct%26mode=render%26action=download%26mode=render", width=854, height=480)
If you want to download the slides: https://osf.io/download/y6em2/
In this project, you will be given the opportunity to explore data from climate models to examine the modeled change in sea ice coverage over time.
The project aims to:
Download, process, and plot data showing modeled sea ice coverage over the historical period within a CMIP6 model climate.
Calculate the total sea ice extent and assess its rate of decline over the recent historical period, and project it into the future under a middle-of-the-road emissions scenario.
Assess the dependence of future projections on emissions scenario, e.g. to assess whether any emissions scenario is sufficient to keep late-summer sea ice in the Arctic.
Examine the spatial and seasonal variation of sea ice and how this changes during its decline with warming.
We also include a dataset of satellite observations, in case you would like to check the realism of the model’s representation of sea ice in the recent historical period.
Project Template#

Data Exploration Notebook#
Project Setup#
# google colab installs
# !pip install --quiet cartopy xmip intake-esm
# Imports
import numpy as np
import matplotlib.pyplot as plt
import xarray as xr
import dask
import cartopy.crs as ccrs
import cartopy.feature as cfeature
from xmip.preprocessing import combined_preprocessing
from xmip.utils import google_cmip_col
from xmip.postprocessing import match_metrics
# @title Figure settings
#import ipywidgets as widgets # interactive display
%config InlineBackend.figure_format = 'retina'
plt.style.use("https://raw.githubusercontent.com/neuromatch/climate-course-content/main/cma.mplstyle")
# Helper functions
import os
import pooch
import tempfile
def pooch_load(filelocation=None, filename=None, processor=None):
shared_location = "/home/jovyan/shared/Data/projects/SeaIce" # this is different for each day
user_temp_cache = tempfile.gettempdir()
if os.path.exists(os.path.join(shared_location, filename)):
file = os.path.join(shared_location, filename)
else:
file = pooch.retrieve(
filelocation,
known_hash=None,
fname=os.path.join(user_temp_cache, filename),
processor=processor,
)
return file
CESM2-WACCM: Climate model simulations of sea ice concentration#
Here we use the output from CESM2-WACCM, the Community Earth System Model (version 2, CESM2), with the Whole Atmosphere Community Climate Model (WACCM) as its atmosphere component.
We use the historical scenario, which runs with historical forcings from 1850 to 2014. Note that this scenario is just one instance of internal variability in a world forced by historical GHGs.
A note on the sea ice output for CMIP6 models:
The Sea Ice component of models is generally output on the ocean grid, which is normally not a simple lat/lon grid, unlike many atmosphere model components. Here we use the variable siconca which stands for sea ice concentration atmosphere - this is the sea ice concentration re-gridded onto the model’s atmosphere grid and is somewhat easier to work with.
Let’s search the CMIP6 catalog for some sea ice concentration (siconca) data from the CESM Earth System Model. We pick a certain ensemble member (r1i1p1f1) to reduce the amount of data to download. At first, our scenarios of interest are the historical and the middle-of-the-road ssp245 ones. As we get the data on the native grid (gn), we must also download the grid cell area in the next step.
Hint: for a detailed explanation of the following xmip functionalities and other CMIP6 related terms, please refer to:
W1D5 Tutorial 7,
W2D1 Tutorial 1,
our CMIP Resource bank,
xmip’s tutorials
this lecture by Ryan Abernathy, Professor of Earth and Environmental Sciences at Columbia University
The following procedure only works locally. If you are working on the JupyterHub or Colab, please skip the next to cells and retrieve the data from OSF.
# create a collection object from the Google Cloud Storage
col = google_cmip_col()
# search via keys
cat = col.search(
source_id=["CESM2-WACCM"],
variable_id=["siconca"],
member_id="r1i1p1f1",
#table_id="SImon",
grid_label="gn",
experiment_id=["historical", "ssp245"],
#, "ssp126", "ssp585"],
require_all_on=["experiment_id", "variable_id"]
)
# key word arguments that allow efficient and useful preprocessing
kwargs = {'zarr_kwargs':{
'consolidated':True,
'use_cftime':True
},
'aggregate':False,
'preprocess':combined_preprocessing
}
# create a dictionary of the datasets from the catalog entries
ds_dict = cat.to_dataset_dict(**kwargs)
list(ds_dict.keys())
/home/runner/micromamba/envs/climatematch/lib/python3.11/site-packages/intake_esm/__init__.py:6: UserWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html. The pkg_resources package is slated for removal as early as 2025-11-30. Refrain from using this package or pin to Setuptools<81.
from pkg_resources import DistributionNotFound, get_distribution
--> The keys in the returned dictionary of datasets are constructed as follows:
'activity_id.institution_id.source_id.experiment_id.member_id.table_id.variable_id.grid_label.zstore.dcpp_init_year.version'
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
['CMIP.NCAR.CESM2-WACCM.historical.r1i1p1f1.SImon.siconca.gn.gs://cmip6/CMIP6/CMIP/NCAR/CESM2-WACCM/historical/r1i1p1f1/SImon/siconca/gn/v20190507/.20190507',
'ScenarioMIP.NCAR.CESM2-WACCM.ssp245.r1i1p1f1.SImon.siconca.gn.gs://cmip6/CMIP6/ScenarioMIP/NCAR/CESM2-WACCM/ssp245/r1i1p1f1/SImon/siconca/gn/v20190815/.20190815']
# repeat the procedure with the grid cell area
cat_metric = col.search(
source_id=['CESM2-WACCM'],
variable_id='areacella',
member_id="r1i1p1f1",
experiment_id=["historical", "ssp245"]
)
ddict_metrics = cat_metric.to_dataset_dict(**kwargs)
list(ddict_metrics.keys())
--> The keys in the returned dictionary of datasets are constructed as follows:
'activity_id.institution_id.source_id.experiment_id.member_id.table_id.variable_id.grid_label.zstore.dcpp_init_year.version'
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
['CMIP.NCAR.CESM2-WACCM.historical.r1i1p1f1.fx.areacella.gn.gs://cmip6/CMIP6/CMIP/NCAR/CESM2-WACCM/historical/r1i1p1f1/fx/areacella/gn/v20190227/.20190227',
'ScenarioMIP.NCAR.CESM2-WACCM.ssp245.r1i1p1f1.fx.areacella.gn.gs://cmip6/CMIP6/ScenarioMIP/NCAR/CESM2-WACCM/ssp245/r1i1p1f1/fx/areacella/gn/v20190815/.20190815']
Execute the following two cells to retrieve the sea ice concentration data from the OSF cloud storage. This is only necessary for the JupyterHub or in the Colab environment. Please adapt the preprocessing accordingly…
# Code to retrieve and load the data if downloading from google cloud storage fails
link_id = 'bnjvp' # historical
#link_id = '4uytf' # ssp126
#link_id = '89tp2' # ssp245
#link_id = '' # ssp585
CMIP6_url = f"https://osf.io/download/{link_id}/"
siconca_fname = 'CMIP_NCAR_CESM2-WACCM_historical_r1i1p1f1_SImon_siconca_gn.nc'
#siconca_fname = 'CMIP_NCAR_CESM2-WACCM_ssp126_r1i1p1f1_SImon_siconca_gn.nc'
#siconca_fname = 'CMIP_NCAR_CESM2-WACCM_ssp245_r1i1p1f1_SImon_siconca_gn.nc'
#siconca_fname = 'CMIP_NCAR_CESM2-WACCM_ssp585_r1i1p1f1_SImon_siconca_gn.nc'
SI_ds_unmatched = xr.open_dataset(pooch_load(CMIP6_url, siconca_fname))
Downloading data from 'https://osf.io/download/bnjvp/' to file '/tmp/CMIP_NCAR_CESM2-WACCM_historical_r1i1p1f1_SImon_siconca_gn.nc'.
SHA256 hash of downloaded file: 227d103e483532f5f9ff8c076198be88cb4ade36083a7e9fec9fec39c61dfec8
Use this value as the 'known_hash' argument of 'pooch.retrieve' to ensure that the file hasn't changed if it is downloaded again in the future.
# Code to retrieve and load the metric data if downloading from google cloud storage fails
link_id = 'hgju4'
CMIP6_url = f"https://osf.io/download/{link_id}/"
metric_fname = 'CMIP_NCAR_CESM2-WACCM_historical_r1i1p1f1_fx_areacella_gn.nc'
SI_ds_metric = xr.open_dataset(pooch_load(CMIP6_url, metric_fname))
Downloading data from 'https://osf.io/download/hgju4/' to file '/tmp/CMIP_NCAR_CESM2-WACCM_historical_r1i1p1f1_fx_areacella_gn.nc'.
SHA256 hash of downloaded file: 84085fd73d372f311979fd908cf3e08f625e35c3c459b2d9c2f0ff15bf9e935e
Use this value as the 'known_hash' argument of 'pooch.retrieve' to ensure that the file hasn't changed if it is downloaded again in the future.
The following preprocessing only works locally after retrieving data from Googles CMIP6 catalog. If you are working on the JupyterHub or Colab, please code your own preprocessing procedure.
#ddict_metrics[CMIP.NCAR.CESM2-WACCM.historical.r1i1p1f1.fx.areacella.gn.gs://cmip6/CMIP6/CMIP/NCAR/CESM2-WACCM/historical/r1i1p1f1/fx/areacella/gn/v20190227/.20190227']
ddict_metrics[list(ddict_metrics.keys())[0]]
<xarray.Dataset> Size: 3MB
Dimensions: (member_id: 1, dcpp_init_year: 1, y: 192, x: 288, nbnd: 2)
Coordinates:
* y (y) float64 2kB -90.0 -89.06 -88.12 ... 88.12 89.06 90.0
* x (x) float64 2kB 0.0 1.25 2.5 3.75 ... 356.2 357.5 358.8
lon_bounds (x, nbnd, y) float64 885kB dask.array<chunksize=(288, 2, 192), meta=np.ndarray>
lat_bounds (y, nbnd, x) float64 885kB dask.array<chunksize=(192, 2, 288), meta=np.ndarray>
* nbnd (nbnd) int64 16B 0 1
lon (x, y) float64 442kB 360.0 360.0 360.0 ... 358.8 358.8 358.8
lat (x, y) float64 442kB -90.0 -89.06 -88.12 ... 89.06 90.0
* member_id (member_id) object 8B 'r1i1p1f1'
* dcpp_init_year (dcpp_init_year) float64 8B nan
Data variables:
areacella (member_id, dcpp_init_year, y, x) float32 221kB dask.array<chunksize=(1, 1, 192, 288), meta=np.ndarray>
Attributes: (12/58)
Conventions: CF-1.7 CMIP-6.2
activity_id: CMIP
branch_method: standard
branch_time_in_child: 674885.0
branch_time_in_parent: 20075.0
case_id: 4
... ...
intake_esm_attrs:variable_id: areacella
intake_esm_attrs:grid_label: gn
intake_esm_attrs:zstore: gs://cmip6/CMIP6/CMIP/NCAR/CESM2-WACCM/...
intake_esm_attrs:version: 20190227
intake_esm_attrs:_data_format_: zarr
intake_esm_dataset_key: CMIP.NCAR.CESM2-WACCM.historical.r1i1p1...# add the grid cell area metric to both scenario data sets
ddict_matched = match_metrics(ds_dict, ddict_metrics, ['areacella'])
list(ddict_matched.keys())
['CMIP.NCAR.CESM2-WACCM.historical.r1i1p1f1.SImon.siconca.gn.gs://cmip6/CMIP6/CMIP/NCAR/CESM2-WACCM/historical/r1i1p1f1/SImon/siconca/gn/v20190507/.20190507',
'ScenarioMIP.NCAR.CESM2-WACCM.ssp245.r1i1p1f1.SImon.siconca.gn.gs://cmip6/CMIP6/ScenarioMIP/NCAR/CESM2-WACCM/ssp245/r1i1p1f1/SImon/siconca/gn/v20190815/.20190815']
# select the historical scenario and print its summary
SI_ds = ddict_matched['CMIP.NCAR.CESM2-WACCM.historical.r1i1p1f1.SImon.siconca.gn.gs://cmip6/CMIP6/CMIP/NCAR/CESM2-WACCM/historical/r1i1p1f1/SImon/siconca/gn/v20190507/.20190507']
SI_ds
<xarray.Dataset> Size: 441MB
Dimensions: (member_id: 1, dcpp_init_year: 1, time: 1980, y: 192,
x: 288, nbnd: 2)
Coordinates:
* y (y) float64 2kB -90.0 -89.06 -88.12 ... 88.12 89.06 90.0
* x (x) float64 2kB 0.0 1.25 2.5 3.75 ... 356.2 357.5 358.8
* time (time) object 16kB 1850-01-15 12:00:00 ... 2014-12-15 12:...
lon_bounds (x, nbnd, y) float64 885kB dask.array<chunksize=(288, 2, 192), meta=np.ndarray>
lat_bounds (y, nbnd, x) float64 885kB dask.array<chunksize=(192, 2, 288), meta=np.ndarray>
time_bounds (time, nbnd) object 32kB dask.array<chunksize=(1980, 2), meta=np.ndarray>
* nbnd (nbnd) int64 16B 0 1
lon (x, y) float64 442kB 360.0 360.0 360.0 ... 358.8 358.8 358.8
lat (x, y) float64 442kB -90.0 -89.06 -88.12 ... 89.06 90.0
* member_id (member_id) object 8B 'r1i1p1f1'
* dcpp_init_year (dcpp_init_year) float64 8B nan
areacella (member_id, dcpp_init_year, y, x) float32 221kB dask.array<chunksize=(1, 1, 192, 288), meta=np.ndarray>
Data variables:
siconca (member_id, dcpp_init_year, time, y, x) float32 438MB dask.array<chunksize=(1, 1, 600, 192, 288), meta=np.ndarray>
Attributes: (12/59)
Conventions: CF-1.7 CMIP-6.2
activity_id: CMIP
branch_method: standard
branch_time_in_child: 674885.0
branch_time_in_parent: 20075.0
case_id: 4
... ...
intake_esm_attrs:variable_id: siconca
intake_esm_attrs:grid_label: gn
intake_esm_attrs:zstore: gs://cmip6/CMIP6/CMIP/NCAR/CESM2-WACCM/...
intake_esm_attrs:version: 20190507
intake_esm_attrs:_data_format_: zarr
intake_esm_dataset_key: CMIP.NCAR.CESM2-WACCM.historical.r1i1p1...# select the ssp245 scenario and print its summary
SI_ds_245 = ddict_matched['ScenarioMIP.NCAR.CESM2-WACCM.ssp245.r1i1p1f1.SImon.siconca.gn.gs://cmip6/CMIP6/ScenarioMIP/NCAR/CESM2-WACCM/ssp245/r1i1p1f1/SImon/siconca/gn/v20190815/.20190815']
SI_ds_245
<xarray.Dataset> Size: 231MB
Dimensions: (member_id: 1, dcpp_init_year: 1, time: 1032, y: 192,
x: 288, nbnd: 2)
Coordinates:
* y (y) float64 2kB -90.0 -89.06 -88.12 ... 88.12 89.06 90.0
* x (x) float64 2kB 0.0 1.25 2.5 3.75 ... 356.2 357.5 358.8
* time (time) object 8kB 2015-01-15 12:00:00 ... 2100-12-15 12:0...
lon_bounds (x, nbnd, y) float64 885kB dask.array<chunksize=(288, 2, 192), meta=np.ndarray>
lat_bounds (y, nbnd, x) float64 885kB dask.array<chunksize=(192, 2, 288), meta=np.ndarray>
time_bounds (time, nbnd) object 17kB dask.array<chunksize=(1032, 2), meta=np.ndarray>
* nbnd (nbnd) int64 16B 0 1
lon (x, y) float64 442kB 360.0 360.0 360.0 ... 358.8 358.8 358.8
lat (x, y) float64 442kB -90.0 -89.06 -88.12 ... 89.06 90.0
* member_id (member_id) object 8B 'r1i1p1f1'
* dcpp_init_year (dcpp_init_year) float64 8B nan
areacella (member_id, dcpp_init_year, y, x) float32 221kB dask.array<chunksize=(1, 1, 192, 288), meta=np.ndarray>
Data variables:
siconca (member_id, dcpp_init_year, time, y, x) float32 228MB dask.array<chunksize=(1, 1, 516, 192, 288), meta=np.ndarray>
Attributes: (12/60)
Conventions: CF-1.7 CMIP-6.2
activity_id: ScenarioMIP
branch_method: standard
branch_time_in_child: 735110.0
branch_time_in_parent: 735110.0
case_id: 966
... ...
intake_esm_attrs:variable_id: siconca
intake_esm_attrs:grid_label: gn
intake_esm_attrs:zstore: gs://cmip6/CMIP6/ScenarioMIP/NCAR/CESM2...
intake_esm_attrs:version: 20190815
intake_esm_attrs:_data_format_: zarr
intake_esm_dataset_key: ScenarioMIP.NCAR.CESM2-WACCM.ssp245.r1i...# let s print the meta data of the areacella that we added as a coordinate before
SI_ds.areacella.attrs
{'cell_methods': 'area: sum',
'comment': 'Cell areas for any grid used to report atmospheric variables and any other variable using that grid (e.g., soil moisture content). These cell areas should be defined to enable exact calculation of global integrals (e.g., of vertical fluxes of energy at the surface and top of the atmosphere).',
'description': 'Cell areas for any grid used to report atmospheric variables and any other variable using that grid (e.g., soil moisture content). These cell areas should be defined to enable exact calculation of global integrals (e.g., of vertical fluxes of energy at the surface and top of the atmosphere).',
'frequency': 'fx',
'id': 'areacella',
'long_name': 'Grid-Cell Area for Atmospheric Grid Variables',
'mipTable': 'fx',
'out_name': 'areacella',
'prov': 'fx ((isd.003))',
'realm': 'atmos land',
'standard_name': 'cell_area',
'time_label': 'None',
'time_title': 'No temporal dimensions ... fixed field',
'title': 'Grid-Cell Area for Atmospheric Grid Variables',
'type': 'real',
'variable_id': 'areacella',
'units': 'm²',
'original_key': 'CMIP.NCAR.CESM2-WACCM.historical.r1i1p1f1.fx.areacella.gn.gs://cmip6/CMIP6/CMIP/NCAR/CESM2-WACCM/historical/r1i1p1f1/fx/areacella/gn/v20190227/.20190227',
'parsed_with': 'xmip/postprocessing/_parse_metric'}
# we also see that it contains the data variable siconca
# let's print the minimum and maximum of this variable to check its format:
print(SI_ds.siconca.min().values)
print(SI_ds.siconca.max().values)
# note that it is formattwd as a percentage not a fraction, ranging from 0 to 100.
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
Could not determine bucket type for bucket name cmip6: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information., falling back to GCSFileSystem
0.0
99.999916
Great, now you are all set to use these model sea ice data to address the questions you are interested in!
Q1:#
Plot the annual mean of Arctic sea ice concentration (SIC) for three example years (e.g., 1996, 2007, 2012) using one CMIP6 model ensemble member.
Hint: Select latitudes of the arctic, years of interest and use cartopy for pretty projections, e.g. ccrs.NorthPolarStereo().
Q2:#
Plot the Arctic total sea ice extent (SIE) as a function of time for the last 40 years. Compute seasonal means of SIE for June-August (JJA) and December-February (DJF).
Hint: We define sea ice extent (SIE) following the convention that a grid cell is ‘sea ice’ with a sea ice concentration higher than 15%.
Extent is hence the sum of the grid cell areas with a concentration above 15%. Use e.g. xr.where() and an appropriate condition to mask the data, then apply the grid cell areas. Have a look at W1D1 Tutorials 8 and 9 to help apply it. Finally, combine results from both data sets into one time series.
Compute seasonal means of SIE for June-August (JJA) and December-February (DJF).
Hint: Apply e.g. groupby("time.season") to calculate seasonal means, note that months have a varying amount of days. Check xarray’s documentation
Q3:#
Repeat the analysis in Q2 for the Antarctic. How does this compare with the respective SIE in the Arctic?
Q4:#
Are there long-term changes (trends) in SIE between 1979-2014 in this model? How do these changes differ across seasons and also between the Arctic and Antarctic?
Hint: from scipy import stats might offer the linear regression techniques that you are looking for. Check its documentation.
Further Reading#
On the CMIP6 projections for arctic sea ice, see Notz et al. (2020), doi.org/10.1029/2019gl086749.
This paper by Steove & Notz, is a nice summary of the observational trends across all seasons, and how they compare to models’ predictions: Steove & Notz (2018), doi.org/10.1088/1748-9326/aade56.
Optional Additional Data Source: Satellite Observations#
National Snow & Ice Data (NSIDC) Gridded Monthly Sea Ice Extent and Concentration, 1850 Onward, Version 2
From 1978, this is satellite passive microwave data. Prior to this, a range of sources are used (e.g. ship logs), but we will subset to only the satellite era here.
The passive microwave observations are the NOAA/NSIDC Climate Data Record of Passive Microwave Sea Ice Concentration, Version 4. This data product uses a combination of two algorithms to generate the sea ice concentration; the NASA Team (NT) algorithm (Cavalieri et al. (1984), doi.org/10.1029/JD089iD04p05355), and the NASA Bootstrap (BT) algorithm (Comiso 1986).
This version has been gridded onto a 1/4 degree latitude-longitude grid, and has been averaged to monthly resolution. It includes only latitudes North of 30°N (so is arctic-only).
# Code to retrieve and load the data
link_id = 'fpr3j'
Sea_ice_conc_obs_url = f"https://osf.io/download/{link_id}/"
Sea_ice_conc_obs_fname = 'G10010_sibt1850_v2.0.nc'
SI_obs_ds = xr.open_dataset(pooch_load(Sea_ice_conc_obs_url, Sea_ice_conc_obs_fname))
# note the use of the chunks keyword. These data come on a high resolution grid,
# so are potentially too large to load into memory. Chunking (using dask)
# avoids this problem. We arbitrarily pick a chunk length of 100 along each dimension.
# we can print a useful summary of the data by calling it:
SI_obs_ds
Downloading data from 'https://osf.io/download/fpr3j/' to file '/tmp/G10010_sibt1850_v2.0.nc'.
SHA256 hash of downloaded file: 090338cc3baa13c91625e6772beb66b5992ba44a864af7ec62c7ec5c22d417d0
Use this value as the 'known_hash' argument of 'pooch.retrieve' to ensure that the file hasn't changed if it is downloaded again in the future.
<xarray.Dataset> Size: 1GB
Dimensions: (latitude: 240, longitude: 1440, time: 2016)
Coordinates:
* latitude (latitude) float32 960B 89.88 89.62 89.38 ... 30.38 30.12
* longitude (longitude) float32 6kB 0.125 0.375 0.625 ... 359.6 359.9
* time (time) object 16kB 1850-01-15 00:00:00 ... 2017-12-15 00...
Data variables:
seaice_conc (time, latitude, longitude) uint8 697MB ...
seaice_source (time, latitude, longitude) uint8 697MB ...
LandRegion_mask (latitude, longitude) uint8 346kB ...
Gridcell_Area (latitude) float32 960B ...
Attributes:
version: 2.0
release_date: February 28, 2019
Conventions: CF-1.4
citation: https://doi.org/10.1111/j.1931-0846.2016.12195.x
dataset_doi: https://nsidc.org/data/g10010# Code to preprocess data
# we will select only the satellite era observations:
SI_obs_ds = SI_obs_ds.where(SI_obs_ds.time.dt.year > 1978, drop=True)
We can now visualize the content of the dataset:
Note that the sea ice concentration is (confusingly!) set to 120% over land.
# We can select and plot the first month
# using .isel(time=0) and inbuilt xarray plotting,
# just to check the data looks reasonable:
SI_obs_ds.isel(time=0).seaice_conc.plot()
<matplotlib.collections.QuadMesh at 0x7fb30c861410>
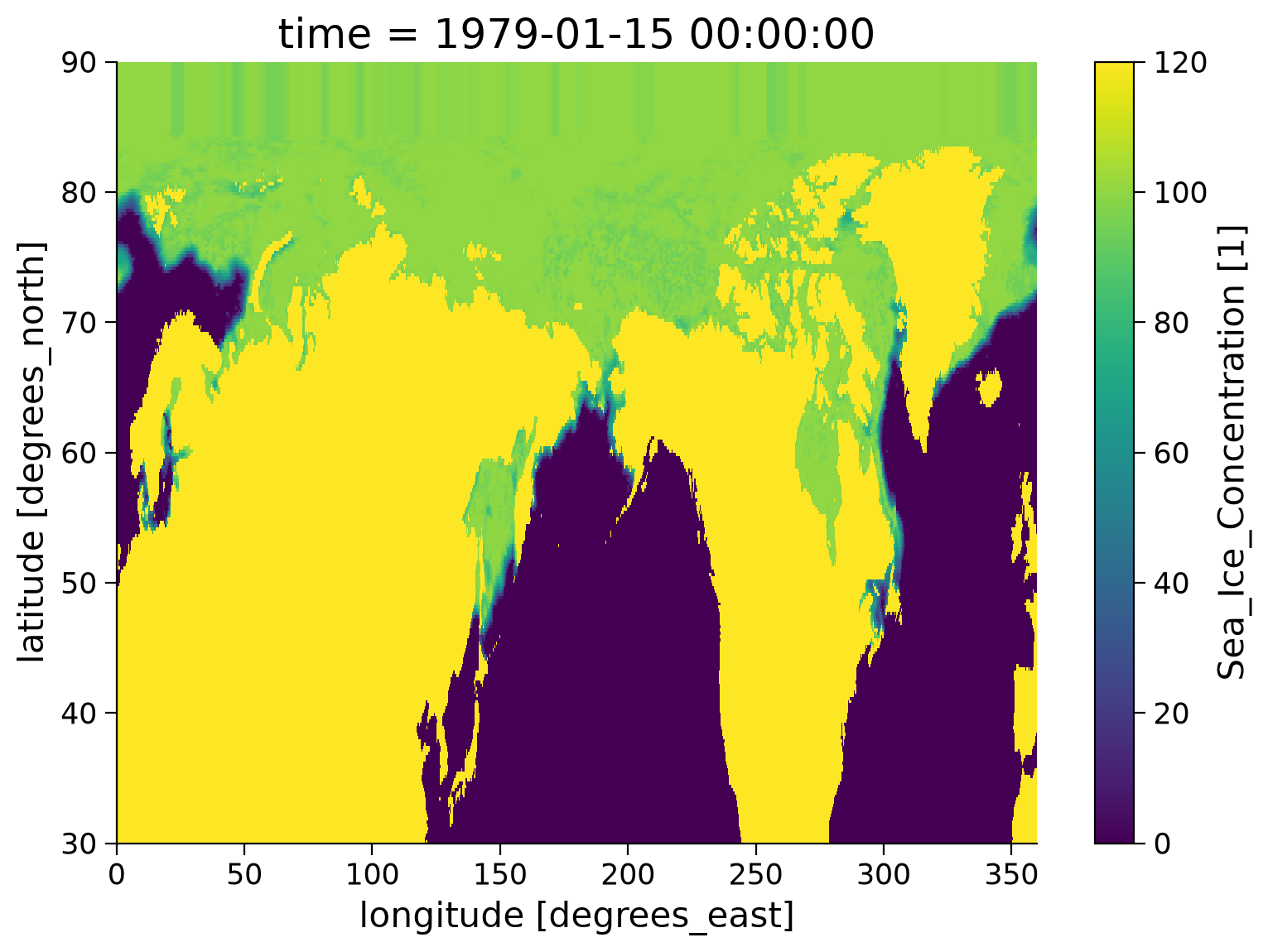
Note that the dataset also includes variables for grid cell area and given in \(\text{km}^2\).
We will need this to convert the spatial data into a time series of the total Arctic sea ice area.
The code below shows how this can be done:
# select only the ocean regions by ignoring any percentages over 100:
SI_obs_ds = SI_obs_ds.where(SI_obs_ds['seaice_conc'] < 101)
# then multiply the ice fraction in each grid cell by the cell area:
# factor of 0.01 servees to convert from percentage to fraction
SI_obs_ds['seaice_area_km2'] = 0.01 * SI_obs_ds['seaice_conc'] * SI_obs_ds['Gridcell_Area']
# finally, we can sum this sea ice area variable over the spatial dimensions to get
# a time series of total Arctic sea ice area:
SI_total_area_obs = SI_obs_ds['seaice_area_km2'].sum(dim=['latitude', 'longitude'])
SI_total_area_obs.plot()
[<matplotlib.lines.Line2D at 0x7fb30dab34d0>]
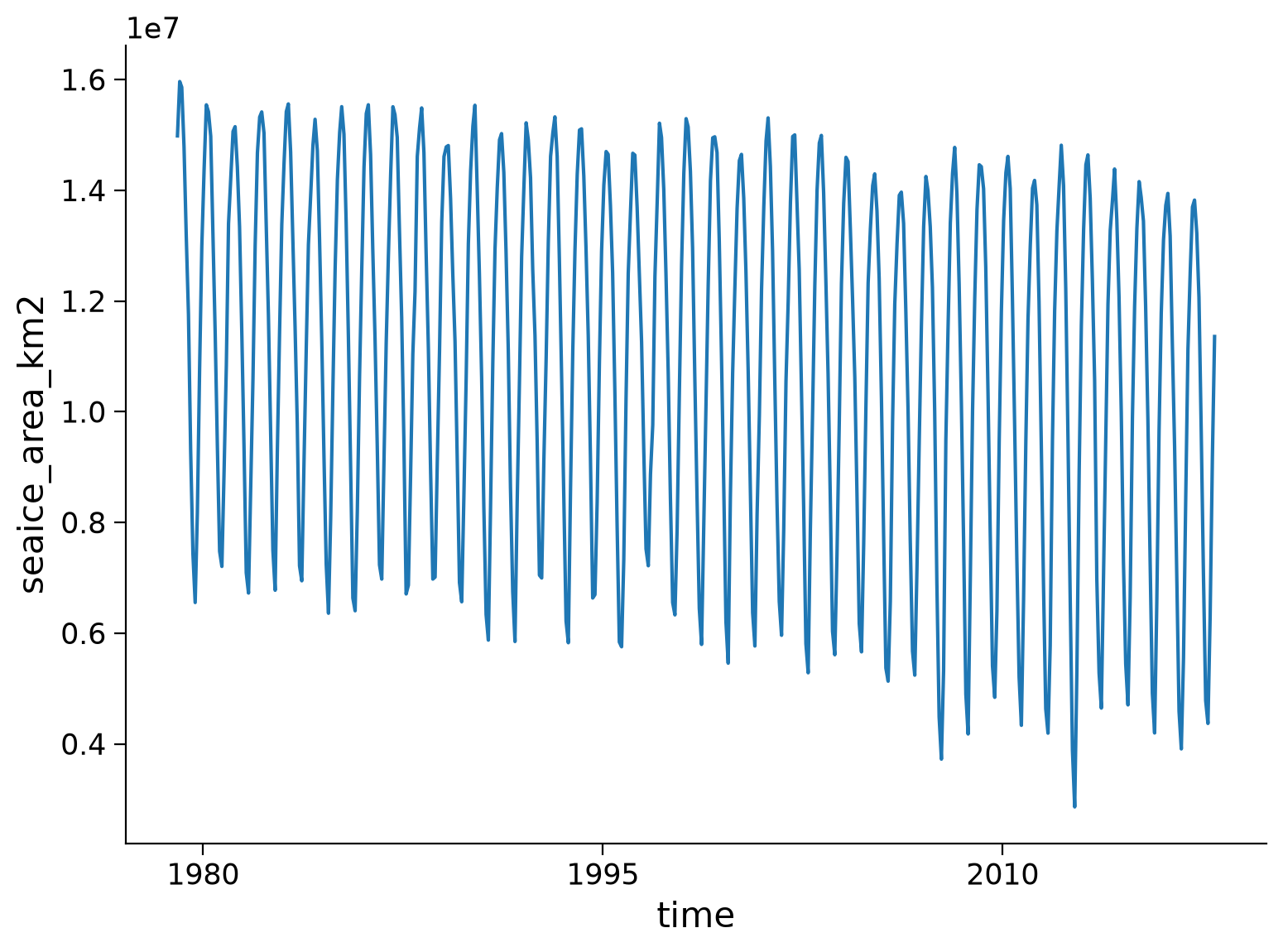
Now you can add the observational decline of sea ice to your analysis if you wish!