![]()

Tutorial 4: Return Levels Using Normal and GEV Distributions#
Week 2, Day 4, Extremes & Variability
Content creators: Matthias Aengenheyster, Joeri Reinders
Content reviewers: Younkap Nina Duplex, Sloane Garelick, Paul Heubel, Zahra Khodakaramimaghsoud, Peter Ohue, Laura Paccini, Jenna Pearson, Agustina Pesce, Derick Temfack, Peizhen Yang, Cheng Zhang, Chi Zhang, Ohad Zivan
Content editors: Paul Heubel, Jenna Pearson, Chi Zhang, Ohad Zivan
Production editors: Wesley Banfield, Paul Heubel, Jenna Pearson, Konstantine Tsafatinos, Chi Zhang, Ohad Zivan
Our 2024 Sponsors: CMIP, NFDI4Earth
Tutorial Objectives#
Estimated timing of tutorial: 30 minutes
Now that we have learned how to create a probability density function (PDF) for the generalized extreme value (GEV) distribution, we can utilize it to calculate return values based on this distribution.
Return levels are computed from a PDF using the cumulative distribution function (CDF), which provides the probability that a randomly drawn variable from our distribution will be less than a certain value X (for our specific variable). Extreme events are rarer, and thus the probability of a precipitation event being at or lower than it is high. For example, if there is a 99% chance of observing a storm with 80mm of rainfall or lower, it means that there is a 1% chance of observing a storm with at least 80mm of rainfall. This implies that the 100-year storm would bring 80mm of rain. In simple terms, the return level is the inverse of the CDF.
By the end of this tutorial, you will be able to:
Estimate return levels using a given quantile and the parameters of a GEV distribution.
Compare return level plots for GEV and normal distributions.
Setup#
# imports
import xarray as xr
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import os
import pooch
import tempfile
from scipy import stats
from scipy.stats import genextreme as gev
Figure Settings#
Show code cell source
# @title Figure Settings
import ipywidgets as widgets # interactive display
%config InlineBackend.figure_format = 'retina'
plt.style.use(
"https://raw.githubusercontent.com/neuromatch/climate-course-content/main/cma.mplstyle"
)
Helper functions#
Show code cell source
# @title Helper functions
def pooch_load(filelocation=None, filename=None, processor=None):
shared_location = "/home/jovyan/shared/Data/tutorials/W2D4_ClimateResponse-Extremes&Variability" # this is different for each day
user_temp_cache = tempfile.gettempdir()
if os.path.exists(os.path.join(shared_location, filename)):
file = os.path.join(shared_location, filename)
else:
file = pooch.retrieve(
filelocation,
known_hash=None,
fname=os.path.join(user_temp_cache, filename),
processor=processor,
)
return file
Section 1: Return Levels and Return Period#
As before let’s load the annual maximum precipitation data from Germany:
# download file: 'precipitationGermany_1920-2022.csv'
filename_precipitationGermany = "precipitationGermany_1920-2022.csv"
url_precipitationGermany = "https://osf.io/xs7h6/download"
data = pd.read_csv(
pooch_load(url_precipitationGermany, filename_precipitationGermany), index_col=0
).set_index("years")
data.columns = ["precipitation"]
precipitation = data.precipitation
And fit the Generalized Extreme Value (GEV) distribution:
shape, loc, scale = gev.fit(precipitation.values, 0)
print(f"Fitted parameters:\nShape: {shape:.5f}, Location: {loc:.5f}, Scale: {scale:.5f}")
Fitted parameters:
Shape: -0.04714, Location: 26.35358, Scale: 7.36941
To compute return levels, you can use the function estimate_return_level(x, location, scale, shape) defined below. In this case, x represents the quantile, the probability of a random value from our distribution being lower. For example, for the 100-year storm, x would be 0.99, and for the 1000-year storm, it would be 0.999.
This utility function takes a given quantile and the GEV parameters (loc, scale, shape) and computes the corresponding return level.
def estimate_return_level(quantile, loc, scale, shape):
level = loc + scale / shape * (1 - (-np.log(quantile)) ** (shape))
return level
Now, let’s utilize this function to calculate the 2-year return level, which represents the precipitation level we anticipate with a 50% chance each year.
estimate_return_level(0.5, loc, scale, shape)
29.07803009997505
This function is also available as part of the scipy GEV implementation - here called the “Percent point function” or ppf which you used previously to make the quantile-quantile plots in the last tutorial.
gev.ppf(0.5, shape, loc=loc, scale=scale)
29.07803009997506
To make things easier, let’s replace x with the formula \(1-(1/\text{return period})\). Note this is different than the exceedance probability discussed in Tutorial 2. So for a 100-year storm, we would use \(1-(1/100) = 0.99\).
Let us compute return levels for the 100- and 1000-year storms.
estimate_return_level(1 - 1 / 100, loc, scale, shape)
64.20998052543192
estimate_return_level(1 - 1 / 1000, loc, scale, shape)
86.51985389906702
Now we will make a figure in which we plot return levels against return periods:
Create a vector “periods” which is a sequence of 2 to 1000 years (with a step size of 2).
Calculate the associated return levels for those return periods.
Plot the return levels against the return periods. Typically, the return periods go on the x-axis at a log scale.
periods = np.arange(2, 1000, 2)
quantiles = 1 - 1 / periods
levels = estimate_return_level(quantiles, loc, scale, shape)
fig, ax = plt.subplots()
ax.plot(periods, levels, ".-")
ax.set_xlabel("Return Period (years)")
ax.set_ylabel("Return Level (mm/day)")
ax.set_xscale("log")
ax.grid(True)
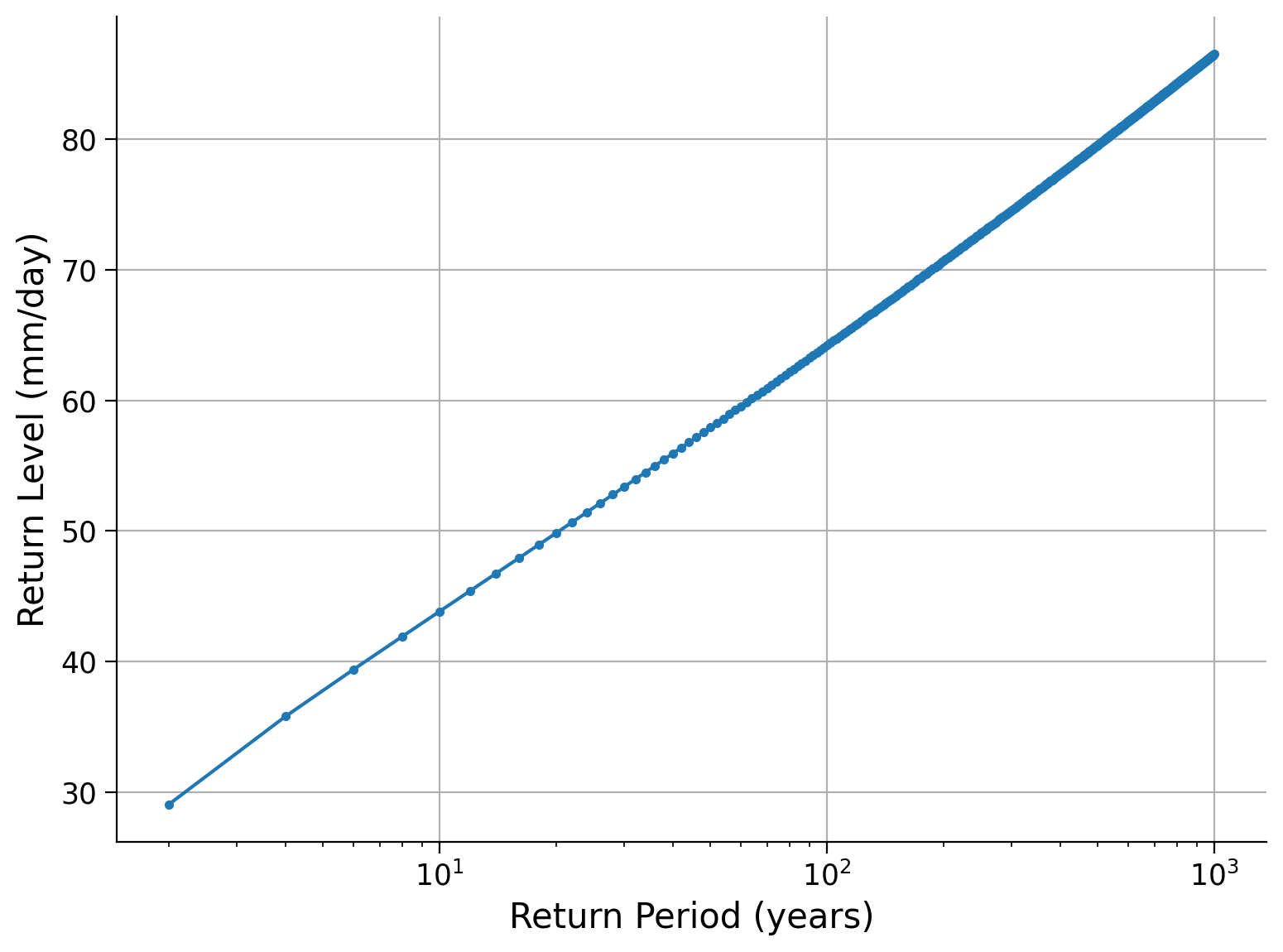
Click to see a description of the plot
Return levels versus return periods calculated from fitted GEV parameters and equal-spaced periods, log scaled on the x-axis. Hence, we can easily access the return level for an X-year event, e.g. 20 year-event corresponds to an annual maximum precipitation of 70 millimeters per day.Coding Exercise 1#
Compute and plot the 50-, 100-, 500- and 1000-year return levels based on a normal distribution and based on the Normal and GEV distributions.
Plot these three things:
the empirical return level
the estimate based on a normal distribution
the estimate based on a GEV distribution
Note that you can get the empirical return levels from tutorial 2, we will provide this code below.
def empirical_return_level(data):
"""
Compute empirical return level using the algorithm introduced in Tutorial 2
"""
df = pd.DataFrame(index=np.arange(data.size))
# sort the data
df["sorted"] = np.sort(data)[::-1]
# rank via scipy instead to deal with duplicate values
df["ranks_sp"] = np.sort(stats.rankdata(-data))
# find exceedence probability
n = data.size
df["exceedance"] = df["ranks_sp"] / (n + 1)
# find return period
df["period"] = 1 / df["exceedance"]
df = df[::-1]
out = xr.DataArray(
dims=["period"],
coords={"period": df["period"]},
data=df["sorted"],
name="level",
)
return out
# setup plots
fig, ax = plt.subplots()
# get empirical return levels and plot them
_ = ...
# create vector of years
years = np.arange(1.1, 100, 0.1)
# calculate and plot the normal return levels
_ = ...
# calculate and plot the GEV distribution, note the negtive shape parameter
_ = ...
# set x axis to log scale
ax.set_xscale("log")
# show legend
ax.legend(["empirical", "normal", "GEV"])
<matplotlib.legend.Legend at 0x7f0b01c0daf0>

Example output:
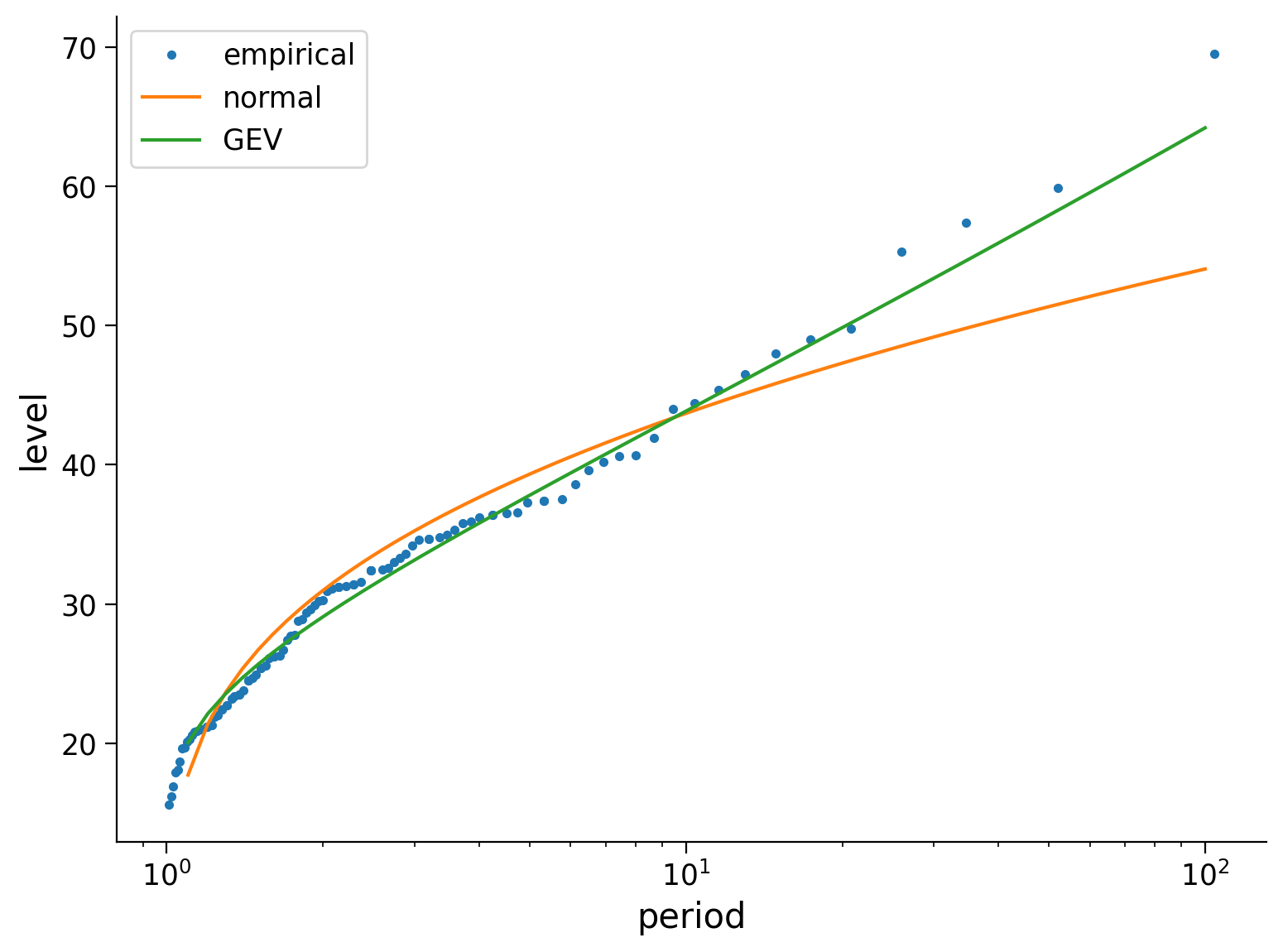
Question 1#
What can you say about the plot and how the distributions describe the data? How do the distributions differ? At short/long return periods? What will happen at even longer return periods?
Bonus: Find Confidence Intervals#
When computing return levels of extreme events - or really when doing any quantitative assessment in science - it is useful and essential to provide uncertainty estimates, that is how much the result may be expected to fluctuate around the central estimate.
In Tutorial 2 the exercise discussed one approach to construct such uncertainty ranges - bootstrapping. You can now extend this method by resampling the data and re-fitting the GEV, and in doing so generate uncertainty estimates of the GEV parameters and GEV-based return levels.
One possible approach could involve the following steps:
Begin with the
gevclass which can be employed to fit GEV parameters using thegev.fit(data)method. This function returns the three parameters, taking note of a sign change in the shape parameter (as different conventions exist).Determine the number of observations in the data, denoted as N.
Perform resampling by randomly drawing N samples from the data with replacement. This process generates an artificial ensemble that differs from the true data due to resampling.
Estimate the parameters for each resampling.
Utilize the
gev.ppf()function for each parameter set to compute the return level.Visualize the resulting uncertainty bands by plotting multiple lines or calculating confidence intervals using
np.quantile().
# initalize list to store parameters from samples
params = []
# generate 1000 samples by resampling data with replacement
for i in range(1000):
...
# print the estimate of the mean of each parameter and it's confidence intervals
print(
"Mean estimate: ",
np.mean(np.array(params), axis=0),
" and 95% confidence intervals: ",
...,
)
# generate years vector
years = np.arange(1.1, 1000, 0.1)
# intialize list for return levels
levels = []
# calculate return levels for each of the 1000 samples
for i in range(1000):
levels.append(...)
levels = np.array(levels)
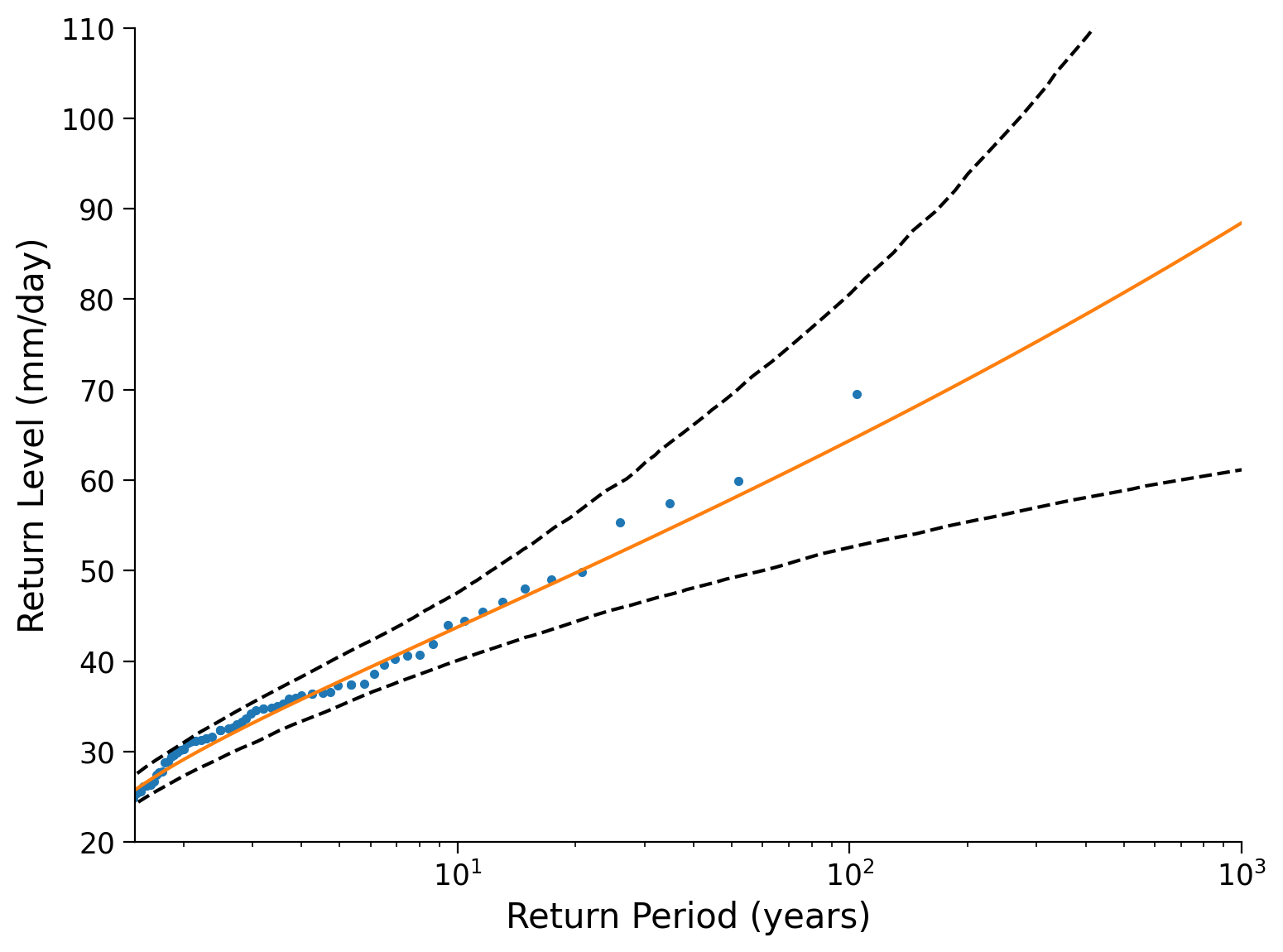
# setup plots
fig, ax = plt.subplots()
# find empirical return levels
_ = ...
# plot return mean levels
_ = ...
# plot confidence intervals
_ = ...
# aesthetics
ax.set_xlim(1.5, 1000)
ax.set_ylim(20, 110)
ax.set_xscale("log")
ax.set_xlabel("Return Period (years)")
ax.set_ylabel("Return Level (mm/day)")
Mean estimate: nan and 95% confidence intervals: Ellipsis
/opt/hostedtoolcache/Python/3.9.19/x64/lib/python3.9/site-packages/numpy/core/fromnumeric.py:3504: RuntimeWarning: Mean of empty slice.
return _methods._mean(a, axis=axis, dtype=dtype,
/opt/hostedtoolcache/Python/3.9.19/x64/lib/python3.9/site-packages/numpy/core/_methods.py:129: RuntimeWarning: invalid value encountered in scalar divide
ret = ret.dtype.type(ret / rcount)
Text(0, 0.5, 'Return Level (mm/day)')
Example output:
Summary#
In this tutorial, you learned how to calculate return values based on the Generalized Extreme Value (GEV) distribution. You learned how they are derived from the cumulative distribution function (CDF), and compared them to those from the normal distribution. Finally, you learned how to create confidence intervals for the parameters that define the GEV distribution for a given dataset.
Resources#
Data from this tutorial uses the 0.25 degree precipitation dataset E-OBS. It combines precipitation observations to generate a gridded (i.e. no “holes”) precipitation over Europe. We used the precipitation data from the gridpoint at 51 N, 6 E.
The dataset can be accessed using the KNMI Climate Explorer here. The Climate Explorer is a great resource to access, manipulate and visualize climate data, including observations and climate model simulations. It is freely accessible - feel free to explore!