![]()

Tutorial 6: Spectral Analysis of Paleoclimate Data#
Week 1, Day 4, Paleoclimate
Content creators: Sloane Garelick
Content reviewers: Yosmely Bermúdez, Dionessa Biton, Katrina Dobson, Maria Gonzalez, Will Gregory, Nahid Hasan, Paul Heubel, Sherry Mi, Beatriz Cosenza Muralles, Brodie Pearson, Jenna Pearson, Chi Zhang, Ohad Zivan
Content editors: Yosmely Bermúdez, Paul Heubel, Zahra Khodakaramimaghsoud, Jenna Pearson, Agustina Pesce, Chi Zhang, Ohad Zivan
Production editors: Wesley Banfield, Paul Heubel, Jenna Pearson, Konstantine Tsafatinos, Chi Zhang, Ohad Zivan
Our 2024 Sponsors: CMIP, NFDI4Earth
Tutorial Objectives#
Estimated timing of tutorial: 25 minutes
In this tutorial, you will manipulate paleoclimate proxy datasets using previously learned computational tools, and apply spectral analysis to further interpret the data.
By the end of this tutorial you will be able to:
Interpret the LR04 benthic δ18O curve and how it records temperature
Perform various spectral analysis methods to assess dominant spectral powers in the LR04 data
Interpret variations in glacial-interglacial cycles recorded by the LR04 δ18O record
Setup#
# installations ( uncomment and run this cell ONLY when using google colab or kaggle )
# !pip install pyleoclim
# imports
# for Google Colab users: you might get a numpy.dtype error here, restart your session and rerun the code and it should solve it.
import pooch
import os
import tempfile
import pandas as pd
import matplotlib.pyplot as plt
import pyleoclim as pyleo
Install and import feedback gadget#
Show code cell source
# @title Install and import feedback gadget
!pip3 install vibecheck datatops --quiet
from vibecheck import DatatopsContentReviewContainer
def content_review(notebook_section: str):
return DatatopsContentReviewContainer(
"", # No text prompt
notebook_section,
{
"url": "https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab",
"name": "comptools_4clim",
"user_key": "l5jpxuee",
},
).render()
feedback_prefix = "W1D4_T6"
Figure Settings#
Show code cell source
# @title Figure Settings
import ipywidgets as widgets # interactive display
%config InlineBackend.figure_format = 'retina'
plt.style.use(
"https://raw.githubusercontent.com/neuromatch/climate-course-content/main/cma.mplstyle"
)
Helper functions#
Show code cell source
# @title Helper functions
def pooch_load(filelocation=None, filename=None, processor=None):
shared_location = "/home/jovyan/shared/Data/tutorials/W1D4_Paleoclimate" # this is different for each day
user_temp_cache = tempfile.gettempdir()
if os.path.exists(os.path.join(shared_location, filename)):
file = os.path.join(shared_location, filename)
else:
file = pooch.retrieve(
filelocation,
known_hash=None,
fname=os.path.join(user_temp_cache, filename),
processor=processor,
)
return file
Video 1: Spectral Analysis#
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Spectral_Analysis_Video")
If you want to download the slides: https://osf.io/download/g7rp4/
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Spectral_Analysis_Slides")
Section 1: Plotting the LR04 δ18O benthic stack#
We will be analyzing a δ18O data from Lisiecki, L. E., and Raymo, M. E. (2005), a stack of 57 globally distributed records of δ18O from benthic foraminifera that spans the past ~5 million years. As we learned from the introductory video, δ18O of foraminifera records temperature due to differences in the isotopic composition of the ocean during glacial and interglacial periods. The δ18O of the ocean (and forams) is more depleted (takes on a smaller values) during interglacials and more enriched (takes on a larger value) during glacials.
Let’s start by importing the data:
# Donwload the data
filename_LR04 = "LR04.csv"
url_LR04 = (
"https://raw.githubusercontent.com/LinkedEarth/PyleoTutorials/main/data/LR04.csv"
)
lr04_data = pd.read_csv(
pooch_load(filelocation=url_LR04, filename=filename_LR04), skiprows=4
)
lr04_data.head()
Downloading data from 'https://raw.githubusercontent.com/LinkedEarth/PyleoTutorials/main/data/LR04.csv' to file '/tmp/LR04.csv'.
SHA256 hash of downloaded file: ad8e9f9df1c716afaa936361d320b4e73f245a59d6f0b4d3c4d722daf2e46b2b
Use this value as the 'known_hash' argument of 'pooch.retrieve' to ensure that the file hasn't changed if it is downloaded again in the future.
| Time (ka) | Benthic d18O (per mil) | Standard error (per mil) | |
|---|---|---|---|
| 0 | 0.0 | 3.23 | 0.03 |
| 1 | 1.0 | 3.23 | 0.04 |
| 2 | 2.0 | 3.18 | 0.03 |
| 3 | 3.0 | 3.29 | 0.03 |
| 4 | 4.0 | 3.30 | 0.03 |
We can now create a Series object containing the data:
ts_lr04 = pyleo.Series(
time=lr04_data["Time (ka)"],
value=lr04_data["Benthic d18O (per mil) "],
time_name="Age",
time_unit="kyr BP",
value_name="Benthic d18O (per mil)",
value_unit="\u2030",
label="LR04",
)
Time axis values sorted in ascending order
This record spans the past ~5 million years (5,000 kyr), but we’re going to focus in on the past 1 million years (1,000 kyr), so let’s create a time slice of just this time period, and plot the time series.
lr04_slice = ts_lr04.slice([0, 1000])
fig, ax = plt.subplots() # assign a new plot axis
lr04_slice.plot(ax=ax, legend=False, invert_yaxis=True)
<Axes: xlabel='Age [kyr BP]', ylabel='Benthic d18O (per mil) [‰]'>
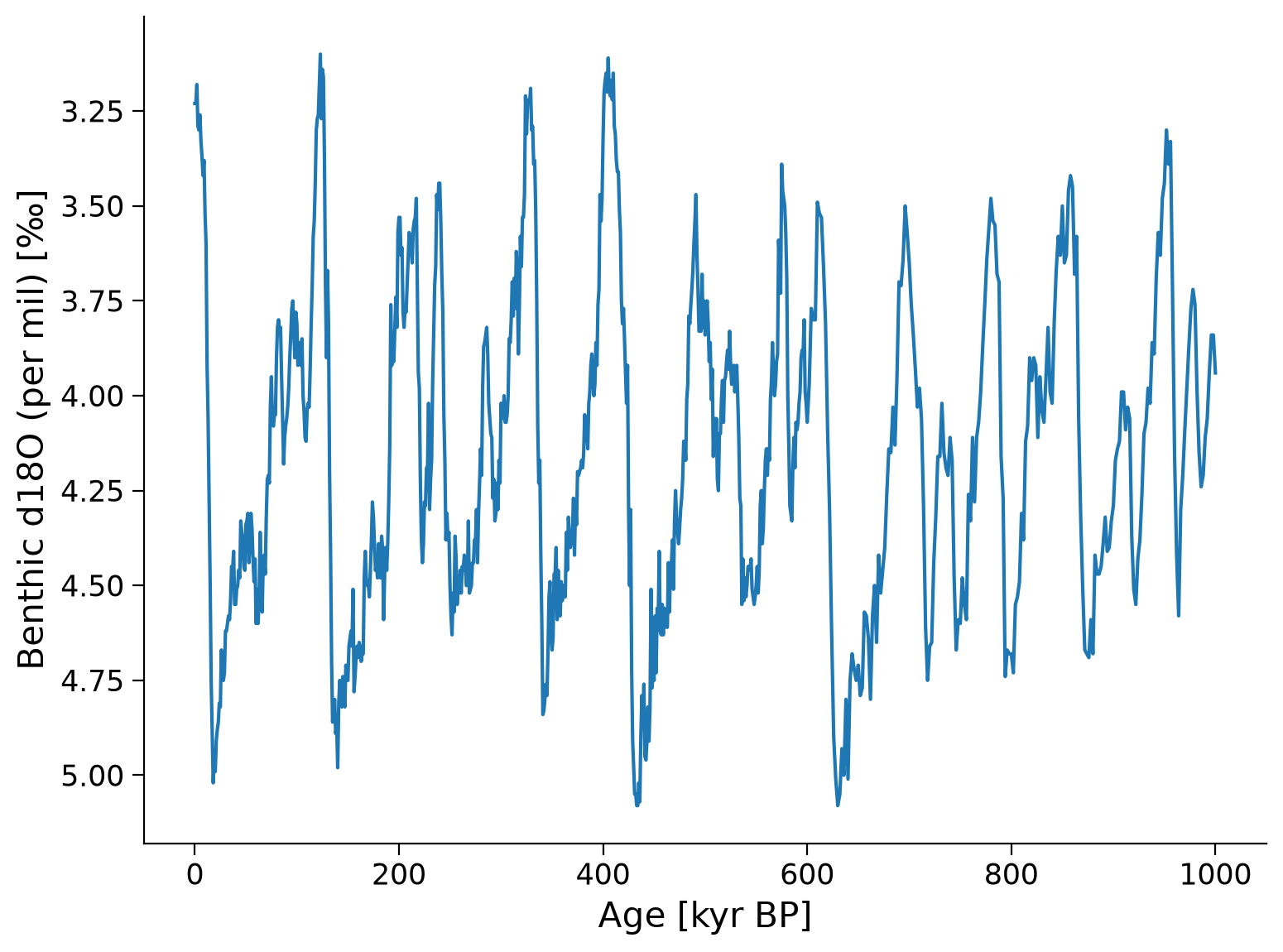
Questions 1#
What patterns do you observe in the record?
Does the amplitude of the glacial-interglacial cycles vary over time?
At what frequency do these glacial-interglacial cycles occur?
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Questions_1")
Section 2: Spectral analysis of the LRO4 δ18O benthic stack#
To better assess the dominant temporal patterns in this record, you can use spectral analysis. As you learned in the introductory video, spectral analysis is a useful data analysis tool in paleoclimate because it allows us to discover underlying periodicities in time series data and can help establish quantitative relationships between forcings and climate variations.
Let’s explore various spectral analysis methods and apply them to the LR04 record to interpret changes in the frequency of glacial-interglacial cycles.
Section 2.1: Spectral Density#
Pyleoclim enables five methods to estimate the spectral density, which will be our main interest in this tutorial:
Basic Periodogram, which uses a Fourier transform. The method has various windowing available to reduce variance.
Welch’s periodogram, a variant of the basic periodogram, which uses Welch’s method of overlapping segments. The periodogram is computed on each segment and averaged together.
Multi-taper method (MTM), which attempts to reduce the variance of spectral estimates by using a small set of tapers rather than the unique data taper or spectral window.
Lomb-Scargle periodogram, an inverse approach designed for unevenly-spaced datasets. Several windows are available and Welch’s segmentation can also be used with this method.
Weighted wavelet Z-transform (WWZ), a wavelet-based method also made for unevenly-spaced datasets.
All of these methods are available through Series.spectral() by changing the method argument. In this tutorial, we’ll focus on Lomb-Scargle and Weighted wavelet Z-transform in more detail. For additional information on the other methods, refer to this notebook from Pyleoclim.
To get a sense of how the estimates of the spectral density using each of these methods compare, we can plot them on the same graph below. Note we must first interpolate to an even grid and then standardize before estimating the spectral density.
fig, ax = plt.subplots()
# basic periodogram
lr04_slice.interp(step=0.5).standardize().spectral(method="periodogram").plot(
ax=ax, xlim=[1000, 5], ylim=[0.001, 1000], label="periodogram"
)
# Welch's periodogram
lr04_slice.interp(step=0.5).standardize().spectral(method="welch").plot(
ax=ax, xlim=[1000, 5], ylim=[0.001, 1000], label="welch"
)
# Multi-taper Method
lr04_slice.interp(step=0.5).standardize().spectral(method="mtm").plot(
ax=ax, xlim=[1000, 5], ylim=[0.001, 1000], label="mtm"
)
# Lomb-Scargle periodogram
lr04_slice.interp(step=0.5).standardize().spectral(method="lomb_scargle").plot(
ax=ax, xlim=[1000, 5], ylim=[0.001, 1000], label="lomb_scargle"
)
# weighted wavelet Z-transform (WWZ)
lr04_slice.interp(step=0.5).standardize().spectral(method="wwz").plot(
ax=ax, xlim=[1000, 5], ylim=[0.001, 1000], label="wwz"
)
<Axes: xlabel='Period [kyr]', ylabel='PSD'>
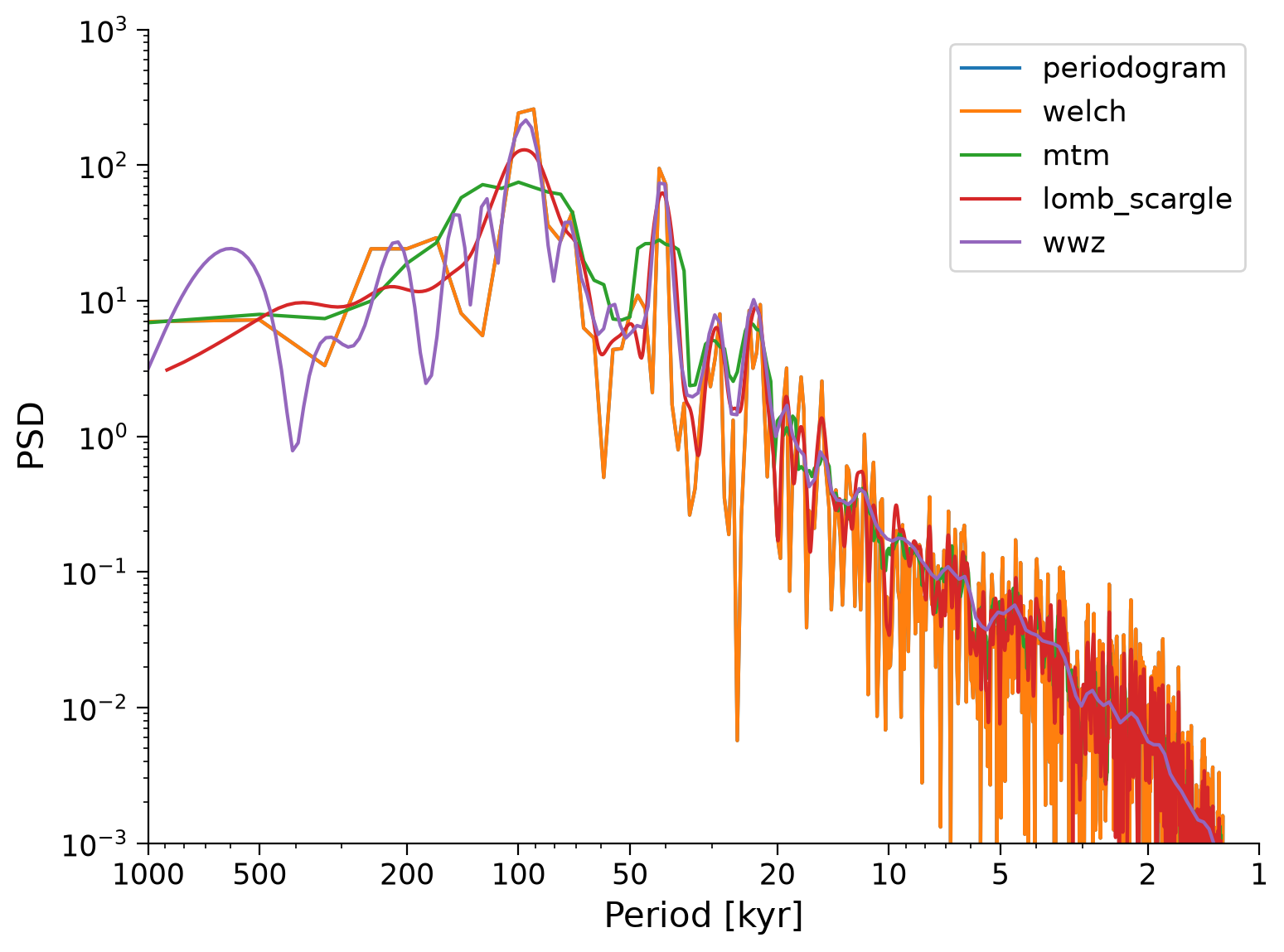
Which method should you choose? The Lomb-Scargle periodogram is the default method in Pyleoclim, and is a good choice for many applications because it:
works with unevenly-spaced time series which are often encountered in paleoclimate data,
seems to give consistent results over parameter ranges,
doesn’t require interpolation, limiting time series manipulation, and
is fairly fast to compute.
We will choose this estimate to analyze.
# Lomb-Scargle periodogram
lr04_ls_sd = lr04_slice.interp(step=0.5).standardize().spectral(method="lomb_scargle")
lr04_ls_sd.plot(xlim=[1000, 5], ylim=[0.001, 1000], label="lomb_scargle")
(<Figure size 1000x400 with 1 Axes>,
<Axes: xlabel='Period [kyr]', ylabel='PSD'>)
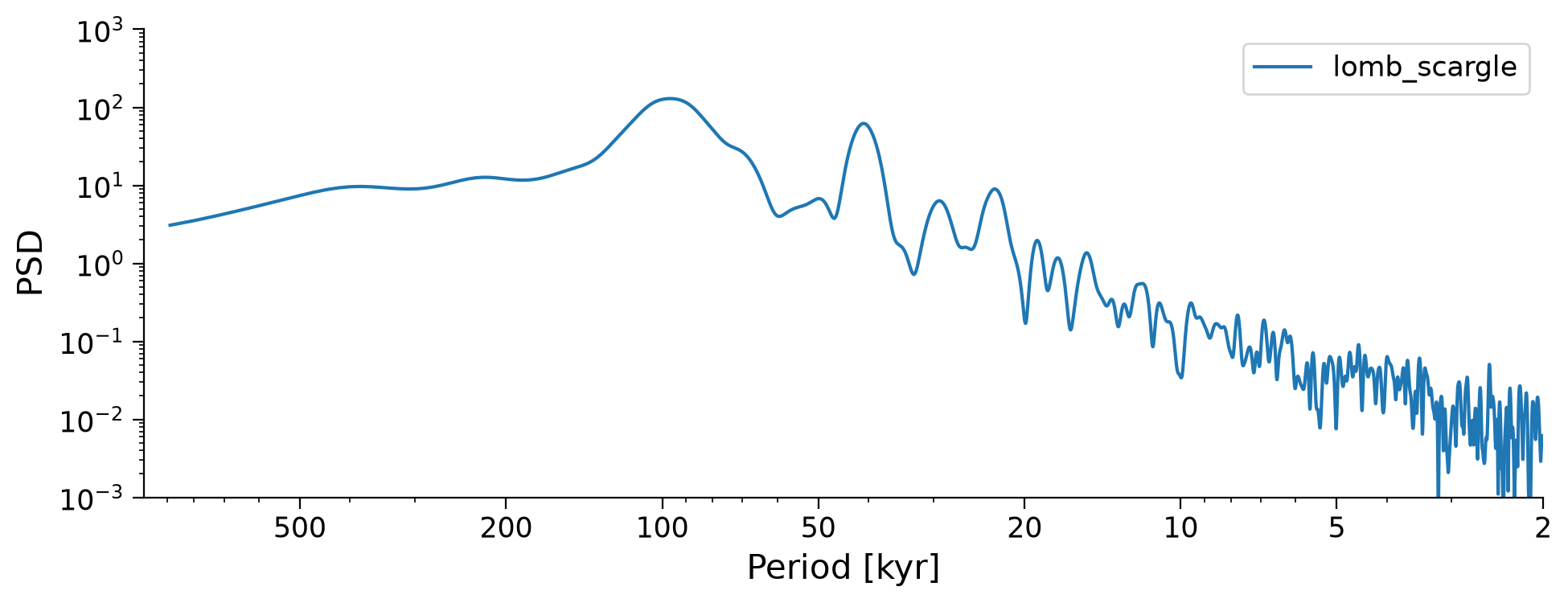
Section 2.2: Significance Testing#
Note that there are few peaks that seem more dominant than others, but which of these peaks are significant? That is, do they stand out more than peaks would from a random time series? To figure that out, we can use the method signif_test. Pyleoclim generates many surrogates of the time series using an AR(1) (Autoregressive Process of order 1 - i.e. a random process). These surrogates serve to identify the probability of a peak not just being from random noise and the likelihood that the peak of the same magnitude would be unlikely to be present in a random dataset. The default number of surrogates generated is 200, and the larger this value, the more smooth and precise our results are.
lr04_ls_sd_sig = lr04_ls_sd.signif_test()
Performing spectral analysis on individual series: 0%| | 0/200 [00:00<?, ?it/s]
Performing spectral analysis on individual series: 0%| | 1/200 [00:05<17:51, 5.38s/it]
Performing spectral analysis on individual series: 2%|▎ | 5/200 [00:07<04:02, 1.24s/it]
Performing spectral analysis on individual series: 3%|▎ | 6/200 [00:07<03:09, 1.02it/s]
Performing spectral analysis on individual series: 4%|▍ | 9/200 [00:09<02:38, 1.20it/s]
Performing spectral analysis on individual series: 5%|▌ | 10/200 [00:09<02:11, 1.44it/s]
Performing spectral analysis on individual series: 6%|▋ | 13/200 [00:11<02:08, 1.45it/s]
Performing spectral analysis on individual series: 7%|▋ | 14/200 [00:11<01:49, 1.70it/s]
Performing spectral analysis on individual series: 8%|▊ | 17/200 [00:13<01:55, 1.59it/s]
Performing spectral analysis on individual series: 9%|▉ | 18/200 [00:14<01:38, 1.84it/s]
Performing spectral analysis on individual series: 10%|█ | 21/200 [00:16<01:47, 1.67it/s]
Performing spectral analysis on individual series: 11%|█ | 22/200 [00:16<01:32, 1.92it/s]
Performing spectral analysis on individual series: 12%|█▎ | 25/200 [00:18<01:42, 1.71it/s]
Performing spectral analysis on individual series: 13%|█▎ | 26/200 [00:18<01:28, 1.96it/s]
Performing spectral analysis on individual series: 14%|█▍ | 28/200 [00:18<01:02, 2.75it/s]
Performing spectral analysis on individual series: 14%|█▍ | 29/200 [00:20<01:51, 1.54it/s]
Performing spectral analysis on individual series: 15%|█▌ | 30/200 [00:20<01:32, 1.83it/s]
Performing spectral analysis on individual series: 16%|█▌ | 31/200 [00:20<01:15, 2.24it/s]
Performing spectral analysis on individual series: 16%|█▋ | 33/200 [00:22<01:47, 1.55it/s]
Performing spectral analysis on individual series: 17%|█▋ | 34/200 [00:22<01:29, 1.86it/s]
Performing spectral analysis on individual series: 18%|█▊ | 35/200 [00:22<01:13, 2.26it/s]
Performing spectral analysis on individual series: 18%|█▊ | 37/200 [00:24<01:44, 1.55it/s]
Performing spectral analysis on individual series: 19%|█▉ | 38/200 [00:24<01:26, 1.87it/s]
Performing spectral analysis on individual series: 20%|█▉ | 39/200 [00:25<01:10, 2.28it/s]
Performing spectral analysis on individual series: 20%|██ | 41/200 [00:26<01:42, 1.55it/s]
Performing spectral analysis on individual series: 21%|██ | 42/200 [00:27<01:24, 1.88it/s]
Performing spectral analysis on individual series: 22%|██▏ | 43/200 [00:27<01:08, 2.30it/s]
Performing spectral analysis on individual series: 22%|██▎ | 45/200 [00:29<01:40, 1.54it/s]
Performing spectral analysis on individual series: 23%|██▎ | 46/200 [00:29<01:21, 1.89it/s]
Performing spectral analysis on individual series: 24%|██▎ | 47/200 [00:29<01:06, 2.31it/s]
Performing spectral analysis on individual series: 24%|██▍ | 49/200 [00:31<01:38, 1.53it/s]
Performing spectral analysis on individual series: 25%|██▌ | 50/200 [00:31<01:19, 1.89it/s]
Performing spectral analysis on individual series: 26%|██▌ | 51/200 [00:31<01:04, 2.31it/s]
Performing spectral analysis on individual series: 26%|██▌ | 52/200 [00:31<00:51, 2.85it/s]
Performing spectral analysis on individual series: 26%|██▋ | 53/200 [00:33<01:50, 1.33it/s]
Performing spectral analysis on individual series: 28%|██▊ | 55/200 [00:33<01:08, 2.12it/s]
Performing spectral analysis on individual series: 28%|██▊ | 56/200 [00:33<00:56, 2.53it/s]
Performing spectral analysis on individual series: 28%|██▊ | 57/200 [00:35<01:48, 1.32it/s]
Performing spectral analysis on individual series: 30%|██▉ | 59/200 [00:35<01:08, 2.07it/s]
Performing spectral analysis on individual series: 30%|███ | 60/200 [00:36<00:56, 2.46it/s]
Performing spectral analysis on individual series: 30%|███ | 61/200 [00:37<01:45, 1.31it/s]
Performing spectral analysis on individual series: 32%|███▏ | 63/200 [00:38<01:06, 2.07it/s]
Performing spectral analysis on individual series: 32%|███▏ | 64/200 [00:38<00:55, 2.43it/s]
Performing spectral analysis on individual series: 32%|███▎ | 65/200 [00:40<01:43, 1.31it/s]
Performing spectral analysis on individual series: 34%|███▎ | 67/200 [00:40<01:04, 2.07it/s]
Performing spectral analysis on individual series: 34%|███▍ | 68/200 [00:40<00:54, 2.41it/s]
Performing spectral analysis on individual series: 34%|███▍ | 69/200 [00:42<01:40, 1.31it/s]
Performing spectral analysis on individual series: 36%|███▌ | 71/200 [00:42<01:01, 2.09it/s]
Performing spectral analysis on individual series: 36%|███▌ | 72/200 [00:42<00:54, 2.35it/s]
Performing spectral analysis on individual series: 36%|███▋ | 73/200 [00:44<01:35, 1.32it/s]
Performing spectral analysis on individual series: 38%|███▊ | 75/200 [00:44<00:59, 2.11it/s]
Performing spectral analysis on individual series: 38%|███▊ | 76/200 [00:44<00:54, 2.29it/s]
Performing spectral analysis on individual series: 38%|███▊ | 77/200 [00:46<01:32, 1.34it/s]
Performing spectral analysis on individual series: 39%|███▉ | 78/200 [00:46<01:12, 1.68it/s]
Performing spectral analysis on individual series: 40%|████ | 80/200 [00:47<00:50, 2.38it/s]
Performing spectral analysis on individual series: 40%|████ | 81/200 [00:48<01:24, 1.41it/s]
Performing spectral analysis on individual series: 41%|████ | 82/200 [00:49<01:09, 1.69it/s]
Performing spectral analysis on individual series: 42%|████▏ | 84/200 [00:49<00:48, 2.38it/s]
Performing spectral analysis on individual series: 42%|████▎ | 85/200 [00:50<01:18, 1.46it/s]
Performing spectral analysis on individual series: 43%|████▎ | 86/200 [00:51<01:06, 1.72it/s]
Performing spectral analysis on individual series: 44%|████▍ | 88/200 [00:51<00:48, 2.31it/s]
Performing spectral analysis on individual series: 44%|████▍ | 89/200 [00:53<01:14, 1.49it/s]
Performing spectral analysis on individual series: 45%|████▌ | 90/200 [00:53<01:02, 1.75it/s]
Performing spectral analysis on individual series: 46%|████▌ | 92/200 [00:53<00:45, 2.35it/s]
Performing spectral analysis on individual series: 46%|████▋ | 93/200 [00:55<01:11, 1.50it/s]
Performing spectral analysis on individual series: 47%|████▋ | 94/200 [00:55<01:00, 1.74it/s]
Performing spectral analysis on individual series: 48%|████▊ | 96/200 [00:56<00:44, 2.36it/s]
Performing spectral analysis on individual series: 48%|████▊ | 97/200 [00:57<01:08, 1.51it/s]
Performing spectral analysis on individual series: 49%|████▉ | 98/200 [00:57<00:58, 1.75it/s]
Performing spectral analysis on individual series: 50%|█████ | 100/200 [00:58<00:42, 2.38it/s]
Performing spectral analysis on individual series: 50%|█████ | 101/200 [00:59<01:05, 1.52it/s]
Performing spectral analysis on individual series: 51%|█████ | 102/200 [00:59<00:55, 1.76it/s]
Performing spectral analysis on individual series: 52%|█████▏ | 104/200 [01:00<00:40, 2.37it/s]
Performing spectral analysis on individual series: 52%|█████▎ | 105/200 [01:01<01:02, 1.52it/s]
Performing spectral analysis on individual series: 53%|█████▎ | 106/200 [01:02<00:52, 1.78it/s]
Performing spectral analysis on individual series: 54%|█████▍ | 108/200 [01:02<00:39, 2.36it/s]
Performing spectral analysis on individual series: 55%|█████▍ | 109/200 [01:04<00:59, 1.52it/s]
Performing spectral analysis on individual series: 55%|█████▌ | 110/200 [01:04<00:50, 1.78it/s]
Performing spectral analysis on individual series: 56%|█████▌ | 112/200 [01:04<00:37, 2.34it/s]
Performing spectral analysis on individual series: 56%|█████▋ | 113/200 [01:06<00:57, 1.51it/s]
Performing spectral analysis on individual series: 57%|█████▋ | 114/200 [01:06<00:48, 1.79it/s]
Performing spectral analysis on individual series: 58%|█████▊ | 116/200 [01:06<00:36, 2.33it/s]
Performing spectral analysis on individual series: 58%|█████▊ | 117/200 [01:08<00:54, 1.51it/s]
Performing spectral analysis on individual series: 59%|█████▉ | 118/200 [01:08<00:45, 1.81it/s]
Performing spectral analysis on individual series: 60%|██████ | 120/200 [01:09<00:34, 2.32it/s]
Performing spectral analysis on individual series: 60%|██████ | 121/200 [01:10<00:52, 1.50it/s]
Performing spectral analysis on individual series: 61%|██████ | 122/200 [01:10<00:42, 1.82it/s]
Performing spectral analysis on individual series: 62%|██████▏ | 124/200 [01:11<00:33, 2.29it/s]
Performing spectral analysis on individual series: 62%|██████▎ | 125/200 [01:12<00:49, 1.51it/s]
Performing spectral analysis on individual series: 63%|██████▎ | 126/200 [01:12<00:40, 1.84it/s]
Performing spectral analysis on individual series: 64%|██████▍ | 128/200 [01:13<00:31, 2.30it/s]
Performing spectral analysis on individual series: 64%|██████▍ | 129/200 [01:14<00:46, 1.52it/s]
Performing spectral analysis on individual series: 65%|██████▌ | 130/200 [01:15<00:37, 1.85it/s]
Performing spectral analysis on individual series: 66%|██████▌ | 132/200 [01:15<00:29, 2.30it/s]
Performing spectral analysis on individual series: 66%|██████▋ | 133/200 [01:17<00:44, 1.52it/s]
Performing spectral analysis on individual series: 67%|██████▋ | 134/200 [01:17<00:35, 1.85it/s]
Performing spectral analysis on individual series: 68%|██████▊ | 136/200 [01:17<00:27, 2.30it/s]
Performing spectral analysis on individual series: 68%|██████▊ | 137/200 [01:19<00:41, 1.51it/s]
Performing spectral analysis on individual series: 69%|██████▉ | 138/200 [01:19<00:33, 1.87it/s]
Performing spectral analysis on individual series: 70%|███████ | 140/200 [01:20<00:26, 2.29it/s]
Performing spectral analysis on individual series: 70%|███████ | 141/200 [01:21<00:39, 1.50it/s]
Performing spectral analysis on individual series: 71%|███████ | 142/200 [01:21<00:31, 1.86it/s]
Performing spectral analysis on individual series: 72%|███████▏ | 144/200 [01:22<00:24, 2.30it/s]
Performing spectral analysis on individual series: 72%|███████▎ | 145/200 [01:23<00:36, 1.50it/s]
Performing spectral analysis on individual series: 73%|███████▎ | 146/200 [01:23<00:28, 1.89it/s]
Performing spectral analysis on individual series: 74%|███████▍ | 148/200 [01:24<00:22, 2.31it/s]
Performing spectral analysis on individual series: 74%|███████▍ | 149/200 [01:25<00:34, 1.50it/s]
Performing spectral analysis on individual series: 76%|███████▌ | 151/200 [01:25<00:21, 2.32it/s]
Performing spectral analysis on individual series: 76%|███████▌ | 152/200 [01:26<00:22, 2.18it/s]
Performing spectral analysis on individual series: 76%|███████▋ | 153/200 [01:27<00:32, 1.43it/s]
Performing spectral analysis on individual series: 78%|███████▊ | 155/200 [01:28<00:19, 2.26it/s]
Performing spectral analysis on individual series: 78%|███████▊ | 156/200 [01:28<00:20, 2.14it/s]
Performing spectral analysis on individual series: 78%|███████▊ | 157/200 [01:30<00:30, 1.41it/s]
Performing spectral analysis on individual series: 80%|███████▉ | 159/200 [01:30<00:18, 2.24it/s]
Performing spectral analysis on individual series: 80%|████████ | 160/200 [01:30<00:18, 2.13it/s]
Performing spectral analysis on individual series: 80%|████████ | 161/200 [01:32<00:27, 1.40it/s]
Performing spectral analysis on individual series: 82%|████████▏ | 163/200 [01:32<00:16, 2.24it/s]
Performing spectral analysis on individual series: 82%|████████▏ | 164/200 [01:32<00:16, 2.14it/s]
Performing spectral analysis on individual series: 82%|████████▎ | 165/200 [01:34<00:25, 1.39it/s]
Performing spectral analysis on individual series: 84%|████████▎ | 167/200 [01:34<00:14, 2.25it/s]
Performing spectral analysis on individual series: 84%|████████▍ | 168/200 [01:35<00:14, 2.14it/s]
Performing spectral analysis on individual series: 84%|████████▍ | 169/200 [01:36<00:22, 1.38it/s]
Performing spectral analysis on individual series: 86%|████████▌ | 172/200 [01:37<00:12, 2.17it/s]
Performing spectral analysis on individual series: 86%|████████▋ | 173/200 [01:38<00:18, 1.50it/s]
Performing spectral analysis on individual series: 88%|████████▊ | 176/200 [01:39<00:11, 2.17it/s]
Performing spectral analysis on individual series: 88%|████████▊ | 177/200 [01:40<00:14, 1.54it/s]
Performing spectral analysis on individual series: 90%|████████▉ | 179/200 [01:40<00:09, 2.24it/s]
Performing spectral analysis on individual series: 90%|█████████ | 180/200 [01:41<00:09, 2.14it/s]
Performing spectral analysis on individual series: 90%|█████████ | 181/200 [01:43<00:13, 1.45it/s]
Performing spectral analysis on individual series: 92%|█████████▏| 183/200 [01:43<00:07, 2.23it/s]
Performing spectral analysis on individual series: 92%|█████████▏| 184/200 [01:43<00:07, 2.13it/s]
Performing spectral analysis on individual series: 92%|█████████▎| 185/200 [01:45<00:10, 1.41it/s]
Performing spectral analysis on individual series: 94%|█████████▎| 187/200 [01:45<00:05, 2.22it/s]
Performing spectral analysis on individual series: 94%|█████████▍| 188/200 [01:45<00:05, 2.14it/s]
Performing spectral analysis on individual series: 94%|█████████▍| 189/200 [01:47<00:07, 1.39it/s]
Performing spectral analysis on individual series: 96%|█████████▌| 191/200 [01:47<00:04, 2.23it/s]
Performing spectral analysis on individual series: 96%|█████████▌| 192/200 [01:47<00:03, 2.14it/s]
Performing spectral analysis on individual series: 96%|█████████▋| 193/200 [01:49<00:05, 1.39it/s]
Performing spectral analysis on individual series: 98%|█████████▊| 195/200 [01:49<00:02, 2.22it/s]
Performing spectral analysis on individual series: 98%|█████████▊| 196/200 [01:50<00:01, 2.11it/s]
Performing spectral analysis on individual series: 98%|█████████▊| 197/200 [01:51<00:02, 1.39it/s]
Performing spectral analysis on individual series: 100%|██████████| 200/200 [01:52<00:00, 2.36it/s]
Performing spectral analysis on individual series: 100%|██████████| 200/200 [01:52<00:00, 1.78it/s]
lr04_ls_sd_sig.plot(xlabel="Period [kyrs]")
(<Figure size 1000x400 with 1 Axes>,
<Axes: xlabel='Period [kyrs]', ylabel='PSD'>)
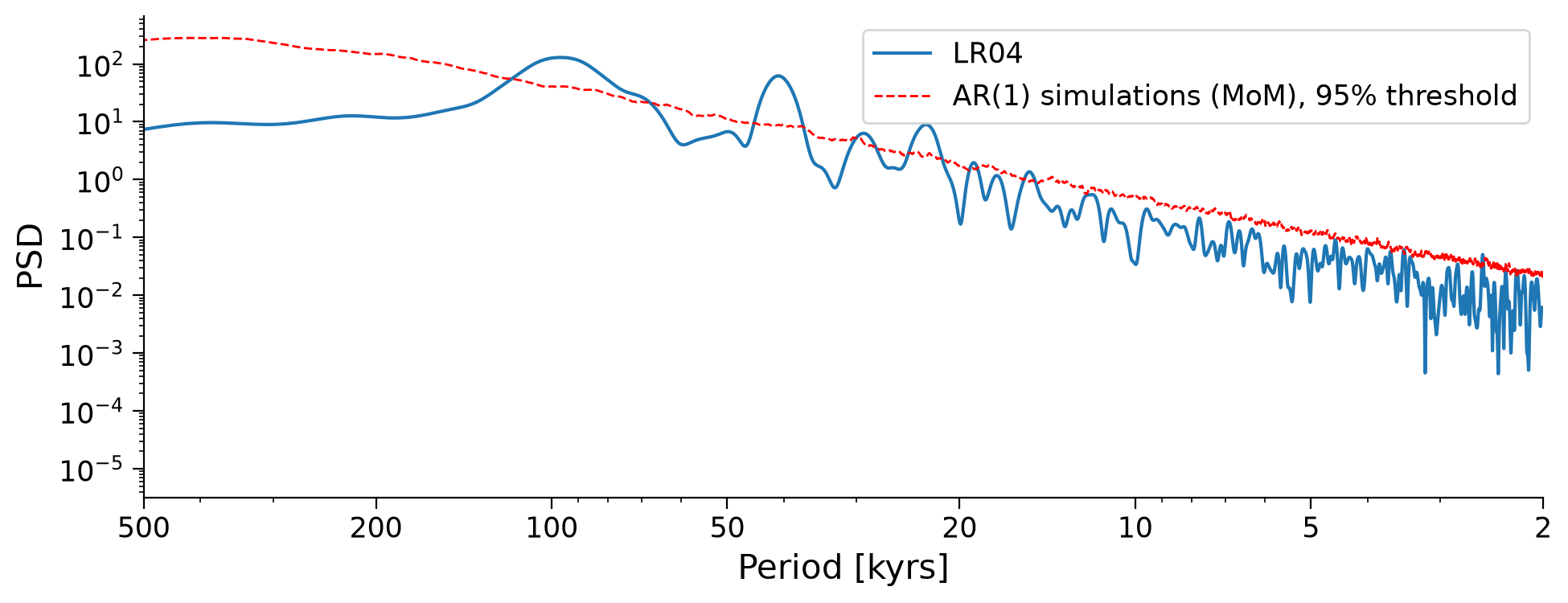
The variable lr04_ls_sd_sig PSD object contains the significant frequencies of the significant peaks from the spectral density of the LR04 data. We can now create the same plot of spectral power, but with only the significant peaks.
NOTE: For this figure, we will plot the x-axis a bit differently. In the previous plot, the x-axis was the “period” but this time the x-axis will be “frequency”, which is the inverse of the period.
fig, ax = plt.subplots()
ax.plot(lr04_ls_sd_sig.frequency, lr04_ls_sd_sig.amplitude)
ax.set_xlim([0.005, 0.07])
ax.set_ylim([0, 200])
ax.set_xlabel("Frequency [1/kyr]")
ax.set_ylabel("Spectra Amplitude")
Text(0, 0.5, 'Spectra Amplitude')
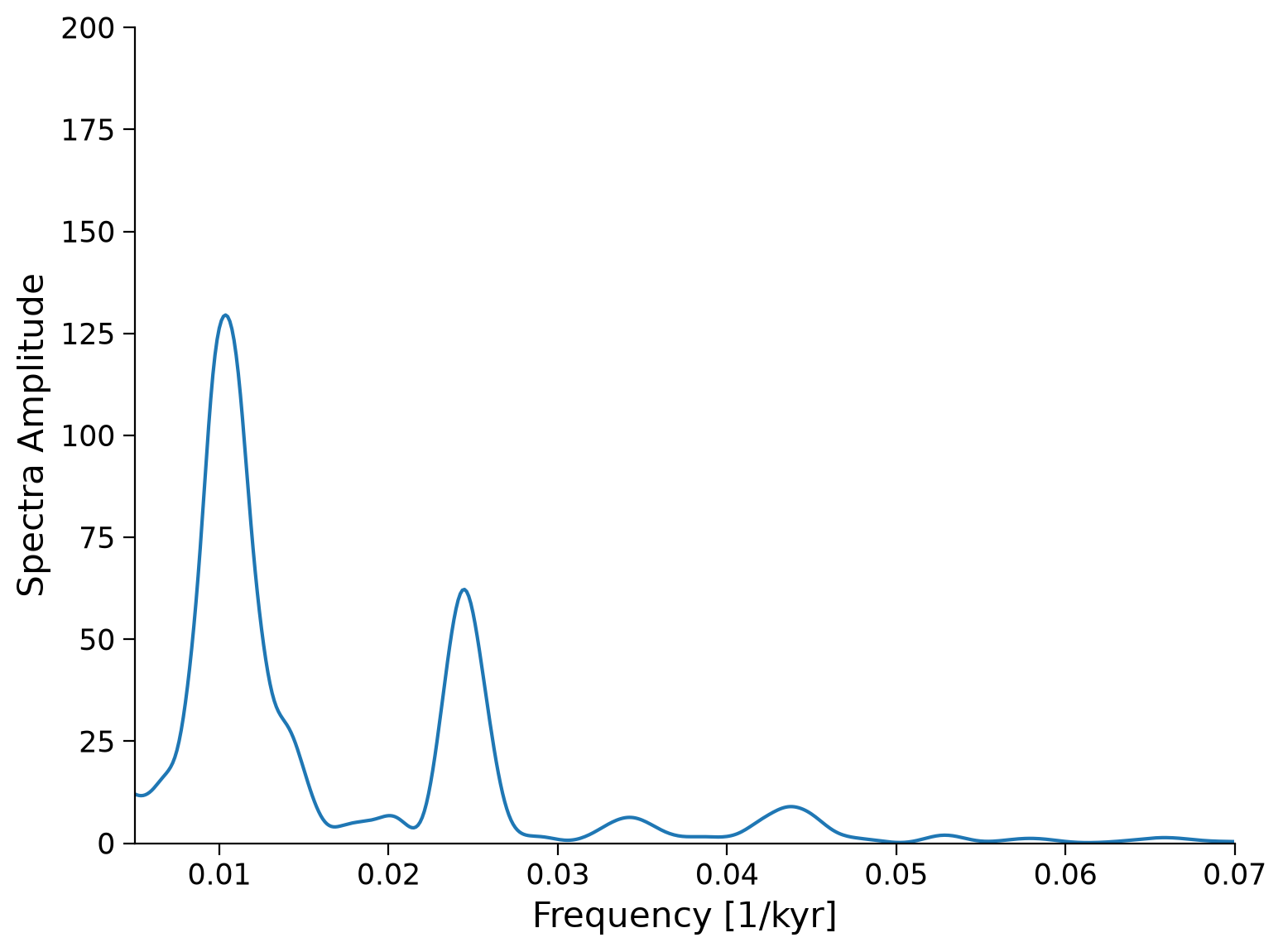
The largest spectral powers in the data occur at a frequencies of ~0.01 and ~0.025, as well as a smaller peak at ~0.042, which correspond to 100 kyr, 40 kyr, and 23 kyr, respectively. Do those periodicities sound familiar?
These are the cycles of eccentricity, obliquity and precession. The presence of spectral powers in the LR04 data at the eccentricity, obliquity and precession frequencies highlights the influence of orbital forcings on glacial-interglacial cycles.
Section 2.3: Wavelet Analysis#
Another related tool we can use to learn more about the climate variability recorded in the data is wavelet analysis. This method allows us to “unfold” a spectrum and look at its evolution over time. In other words, wavelet analysis can help us determine changes in the spectral power over time. For additional details about wavelet analysis, refer to this guide.
There are several ways to access this functionality in Pyleoclim, but here we use summary_plot, which stacks together the timeseries itself in the upper panel, its scalogram (a plot of the magnitude of the wavelet power) in the middle, and the power spectral density (PSD, which we plotted earlier in this tutorial) obtained from summing the wavelet coefficients over time to the right.
# create a scalogram
scal = lr04_slice.interp(step=0.5).standardize().wavelet()
# make plot
lr04_slice.summary_plot(
psd=lr04_ls_sd_sig, scalogram=scal, time_lim=[0, 1000], psd_label="Amplitude"
)
(<Figure size 800x1000 with 4 Axes>,
{'ts': <Axes: xlabel='Age [kyr BP]', ylabel='Benthic d18O (per mil) [‰]'>,
'scal': <Axes: xlabel='Age [kyr BP]', ylabel='Scale [kyrs]'>,
'psd': <Axes: xlabel='Amplitude'>,
'cb': <Axes: xlabel='cwt Amplitude'>})
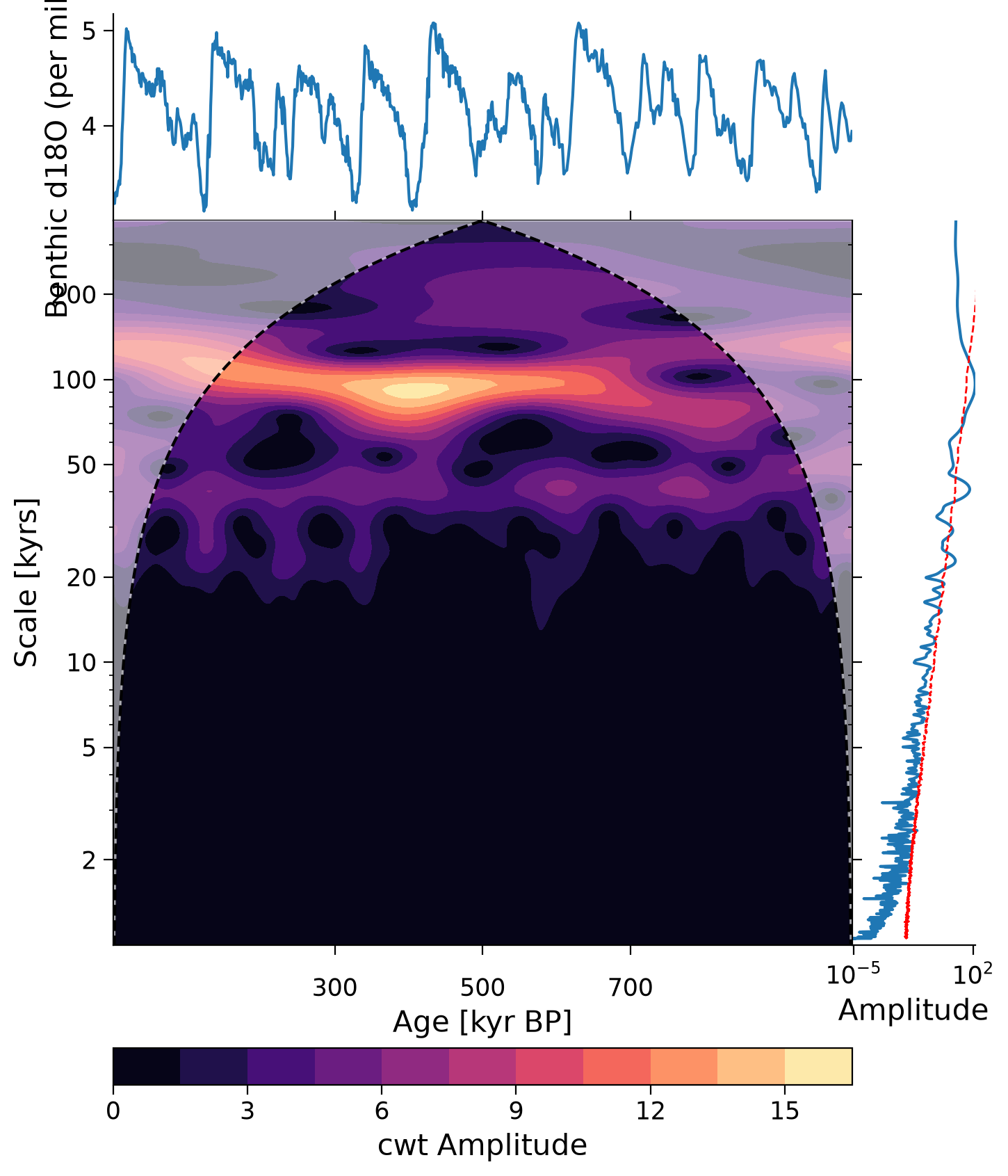
In this wavelet spectrum, the age of the record is on the x-axis, the period is on the y-axis, and the color represents the amplitude of that power spectrum, with yellow indicating a higher power and purple indicating a lower power. The time series on top is the original LR04 δ18O data, and the plot on the right is the spectral analysis and significance test figure we created earlier in this tutorial.
Questions 2.3: Climate Connection#
In the spectral analysis above, the 100 kyr and 40 kyr period are the most dominant. Here, we further see that over the past 1 million years, the 100 kyr cycle is the strongest (as seen by the yellow color at the 100 kyr scale), followed by the 40 kyr cycle (as seen by the light purple color at the 40 kyr scale). You may notice an absence of much color at the 23 kyr scale. What does this suggest about the influence of precession on glacial-interglacial cycles on this timescale?
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Questions_2_3")
Summary#
In this tutorial you learned how to analyze paleoclimate proxy datasets using spectral and wavelet analysis. You were introduced to several spectral analysis methods, identified significant spectral peaks in the spectral density, and looked at the wavelet transform, it’s evolution over time. By the end, you were able to determine the influence of various periods, like the 100 kyr and 40 kyr orbital cycles, on glacial-interglacial cycles.
Resources#
Code for this tutorial is based on existing notebooks from LinkedEarth for spectral analysis and wavelet analysis.
Data from the following sources are used in this tutorial:
Lisiecki, L. E., and Raymo, M. E. (2005), A Pliocene-Pleistocene stack of 57 globally distributed benthic δ18O records, Paleoceanography, 20, PA1003, https://doi.org/10.1029/2004PA001071.