![]()

Tutorial 1: Paleoclimate Proxies#
Week 1, Day 4, Paleoclimate
Content creators: Sloane Garelick
Content reviewers: Yosmely Bermúdez, Katrina Dobson, Maria Gonzalez, Will Gregory, Nahid Hasan, Paul Heubel, Sherry Mi, Beatriz Cosenza Muralles, Brodie Pearson, Jenna Pearson, Chi Zhang, Ohad Zivan
Content editors: Yosmely Bermúdez, Paul Heubel, Zahra Khodakaramimaghsoud, Jenna Pearson, Agustina Pesce, Chi Zhang, Ohad Zivan
Production editors: Wesley Banfield, Paul Heubel, Jenna Pearson, Chi Zhang, Ohad Zivan
Our 2024 Sponsors: CMIP, NFDI4Earth
Tutorial Objectives#
Estimated timing of tutorial: 20 minutes
In this tutorial, you’ll learn about different types of paleoclimate proxies (physical characteristics of the environment that can stand in for direct measurements), the file type they come in, and how to convert these files to more usable formats.
By the end of this tutorial you will be able to:
Understand some types of paleoclimate proxies and archives that exist
Create a global map of locations of proxy paleoclimate records in a specific data network
Setup#
# installations ( uncomment and run this cell ONLY when using google colab or kaggle )
# !pip install cartopy
# !pip install LiPD
# imports
import os
import sys
from io import StringIO
import pandas as pd
import numpy as np
import pooch # to download the PAGES2K data
import matplotlib.pyplot as plt
import tempfile
import lipd
import cartopy.crs as ccrs
import cartopy.feature as cfeature
Install and import feedback gadget#
Show code cell source
# @title Install and import feedback gadget
!pip3 install vibecheck datatops --quiet
from vibecheck import DatatopsContentReviewContainer
def content_review(notebook_section: str):
return DatatopsContentReviewContainer(
"", # No text prompt
notebook_section,
{
"url": "https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab",
"name": "comptools_4clim",
"user_key": "l5jpxuee",
},
).render()
feedback_prefix = "W1D4_T1"
Figure Settings#
Show code cell source
# @title Figure Settings
import ipywidgets as widgets # interactive display
%config InlineBackend.figure_format = 'retina'
plt.style.use(
"https://raw.githubusercontent.com/neuromatch/climate-course-content/main/cma.mplstyle"
)
Helper functions#
Show code cell source
# @title Helper functions
def pooch_load(filelocation=None, filename=None, processor=None):
shared_location = "/home/jovyan/shared/Data/tutorials/W1D4_Paleoclimate" # this is different for each day
user_temp_cache = tempfile.gettempdir()
if os.path.exists(os.path.join(shared_location, filename)):
file = os.path.join(shared_location, filename)
else:
file = pooch.retrieve(
filelocation,
known_hash=None,
fname=os.path.join(user_temp_cache, filename),
processor=processor,
)
return file
# Convert the PAGES2K LiDP files into a pandas.DataFrame
# Function to convert the PAGES2K LiDP files in a pandas.DataFrame
def lipd2df(
lipd_dirpath,
pkl_filepath=None,
col_str=[
"paleoData_pages2kID",
"dataSetName",
"archiveType",
"geo_meanElev",
"geo_meanLat",
"geo_meanLon",
"year",
"yearUnits",
"paleoData_variableName",
"paleoData_units",
"paleoData_values",
"paleoData_proxy",
],
):
"""
Convert a bunch of PAGES2k LiPD files to a `pandas.DataFrame` to boost data loading.
If `pkl_filepath` isn't `None`, save the DataFrame as a pikle file.
Parameters:
----------
lipd_dirpath: str
Path of the PAGES2k LiPD files
pkl_filepath: str or None
Path of the converted pickle file. Default: `None`
col_str: list of str
Name of the variables to extract from the LiPD files
Returns:
-------
df: `pandas.DataFrame`
Converted Pandas DataFrame
"""
# Save the current working directory for later use, as the LiPD utility will change it in the background
work_dir = os.getcwd()
# LiPD utility requries the absolute path
lipd_dirpath = os.path.abspath(lipd_dirpath)
# Load LiPD files
lipds = lipd.readLipd(lipd_dirpath)
# Extract timeseries from the list of LiDP objects
ts_list = lipd.extractTs(lipds)
# Recover the working directory
os.chdir(work_dir)
# Create an empty pandas.DataFrame with the number of rows to be the number of the timeseries (PAGES2k records),
# and the columns to be the variables we'd like to extract
df_tmp = pd.DataFrame(index=range(len(ts_list)), columns=col_str)
# Loop over the timeseries and pick those for global temperature analysis
i = 0
for ts in ts_list:
if (
"paleoData_useInGlobalTemperatureAnalysis" in ts.keys()
and ts["paleoData_useInGlobalTemperatureAnalysis"] == "TRUE"
):
for name in col_str:
try:
df_tmp.loc[i, name] = ts[name]
except:
df_tmp.loc[i, name] = np.nan
i += 1
# Drop the rows with all NaNs (those not for global temperature analysis)
df = df_tmp.dropna(how="all")
# Save the dataframe to a pickle file for later use
if pkl_filepath:
save_path = os.path.abspath(pkl_filepath)
print(f"Saving pickle file at: {save_path}")
df.to_pickle(save_path)
return df
class SupressOutputs(list):
def __enter__(self):
self._stdout = sys.stdout
sys.stdout = self._stringio = StringIO()
return self
def __exit__(self, *args):
self.extend(self._stringio.getvalue().splitlines())
del self._stringio # free up some memory
sys.stdout = self._stdout
Video 1: What is Paleoclimate?#
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_What_is_Paleoclimate_Video")
If you want to download the slides: https://osf.io/download/ae894/
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_What_is_Paleoclimate_Slides")
Section 1: Introduction to PAGES2k#
As we’ve now seen from the introductory video, there are various types of paleoclimate archives and proxies that can be used to reconstruct past changes in Earth’s climate. For example:
Sediment Cores: Sediments deposited in layers within lakes and oceans serve as a record of climate variations over time. Various proxies for past climate are preserved in sediment cores including, pollen, microfossils, charcoal, microscopic organisms, organic molecules, etc.
Ice Cores: Similarly to sediment cores, ice cores capture past climate changes in layers of ice accumulated over time. Common proxies for reconstructing past climate in ice cores include water isotopes, greenhouse gas concentrations of air bubbles in the ice, and dust.
Corals: Corals form annual growth bands within their carbonate skeletons, recording temperature changes over time. Scientists analyze the chemical composition of each layer to reconstruct temperature and salinity. Corals typically preserve relatively short paleoclimate records, but they provide very high-resolution reconstructions (monthly and seasonal) and are therefore valuable for understanding past changes in short-term phenomena.
Speleothems: These are cave formations that result from the deposition of minerals from groundwater. As the water flows into the cave, thin layers of minerals (e.g., calcium carbonate), are deposited. The thickness and chemical composition of speleothem layers can be used to reconstruct climate changes in the past.
Tree Rings: Each year, trees add a new layer of growth, known as a tree ring. These rings record changes in temperature and precipitation. Proxy measurements of tree rings include thickness and isotopes, which reflect annual variability in moisture and temperature.
There are many existing paleoclimate reconstructions spanning a variety of timescales and from global locations. Given the temporal and spatial vastness of existing paleoclimate records, it can be challenging to know what paleoclimate data already exists and where to find it. One useful solution is compiling all existing paleoclimate records for a single climate variable (temperature, greenhouse gas concentration, precipitation, etc.) and over a specific time period (Holocene to present, the past 800,000 years, etc.).
One example of this is the PAGES2k network, which is a community-sourced database of temperature-sensitive proxy records. The database consists of 692 records from 648 locations, that are from a variety of archives (e.g., trees, ice, sediment, corals, speleothems, etc.) and span the Common Era (1 CE to present, i.e., the past ~2,000 years). You can read more about the PAGES2k network, in PAGES 2k Consortium (2017).
In this tutorial, we will explore the types of proxy records in the PAGES2k network and create a map of proxy record locations.
Section 2: Get PAGES2k LiPD Files#
The PAGES2k network is stored in a specific file format known as Linked Paleo Data format (LiPD). LiPD files contain time series information in addition to supporting metadata (e.g., root metadata, location). Pyleoclim (and its dependency package LiPD) leverages this additional information using LiPD-specific functionality.
Data stored in the .lpd format can be loaded directly as a Lipd object. If the data_path points to one LiPD file, lipd.readLipd.() will load the specific record, while if data_path points to a folder of lipd files, lipd.readLipd.() will load the full set of records. This function to read in the data is imbedded in the helper function above used to read the data in and convert it to a more usable format.
The first thing we need to do it to download the data.
# Set the name to save the PAGES2K data
fname = "pages2k_data"
# Download the data
lipd_file_path = pooch.retrieve(
url="https://ndownloader.figshare.com/files/8119937",
known_hash=None,
path="./",
fname=fname,
processor=pooch.Unzip(),
)
Now we can use our helper function lipd2df() to convert the LiPD files to a Pandas dataframe.
NOTE: when you run some of the next code cells to convert the Lipd files to a DataFrame, you will get some error messages. This is fine and the code will still accomplish what it needs to do. The code will also take a few minutes to run, so if it’s taking longer than you’d expect, that’s alright!
# convert all the lipd files into a DataFrame
fname = "pages2k_data"
with SupressOutputs():
pages2k_data = lipd2df(
lipd_dirpath=os.path.join(".", f"{fname}.unzip", "LiPD_Files")
)
The PAGES2k data is now stored as a dataframe and we can view the data to understand different attributes it contains.
# print the top few rows of the PAGES2K data
pages2k_data.head()
| paleoData_pages2kID | dataSetName | archiveType | geo_meanElev | geo_meanLat | geo_meanLon | year | yearUnits | paleoData_variableName | paleoData_units | paleoData_values | paleoData_proxy | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | NAm_091 | NAm-ak058 | tree | 213.0 | 65.2 | -162.2 | [1406.0, 1407.0, 1408.0, 1409.0, 1410.0, 1411.... | AD | trsgi | NA | [0.72, 0.988, 1.018, 1.025, 0.998, 1.093, 1.08... | TRW |
| 1 | Ocn_077 | Ocean2kHR-IndianMafiaDamassa2006 | coral | -6.0 | -8.0167 | 39.5 | [1998.125, 1998.042, 1997.958, 1997.875, 1997.... | AD | d18O | permil | [-3.967, -4.075, -4.001, -3.983, -3.952, -3.81... | d18O |
| 2 | Asi_116 | Asia-TSO | tree | 2000.0 | 44.95 | 142.12 | [1500.0, 1501.0, 1502.0, 1503.0, 1504.0, 1505.... | AD | trsgi | NA | [0.806, 0.783, 1.121, 1.216, 1.073, 1.12, 1.12... | TRW |
| 3 | Ocn_048 | O2kLR-SouthAtlantic.Leduc.2010 | marine sediment | -97.0 | -29.14 | 16.72 | [1938.0, 1918.0, 1898.0, 1879.0, 1859.0, 1839.... | AD | temperature | degC | [16.03, 16.18, 16.15, 16.18, 16.39, 16.39, 16.... | alkenone |
| 4 | Ocn_095 | Ocean2kHR-PacificLinsley2006FijiAB | coral | -10.0 | -16.8167 | 179.2333 | [2001.5, 2000.5, 1999.5, 1998.5, 1997.5, 1996.... | AD | d18O | permil | [-4.81, -4.9775, -4.9623, -4.5623, -4.5566, -4... | d18O |
Section 3: Plotting a Map of Proxy Reconstruction Locations#
Now that we have converted the data into a Pandas dataframe, we can plot the PAGES2k network on a map to understand the spatial distribution of the temperature records and the types of proxies that were measured.
Before generating the plot, we have to define the colours and the marker types that we want to use in the plot. We also need to set a list with the different archive_type names that appear in the data frame.
# list of markers and colors for the different archive_type
markers = ["p", "p", "o", "v", "d", "*", "s", "s", "8", "D", "^"]
colors = [
np.array([1.0, 0.83984375, 0.0]),
np.array([0.73828125, 0.71484375, 0.41796875]),
np.array([1.0, 0.546875, 0.0]),
np.array([0.41015625, 0.41015625, 0.41015625]),
np.array([0.52734375, 0.8046875, 0.97916667]),
np.array([0.0, 0.74609375, 1.0]),
np.array([0.25390625, 0.41015625, 0.87890625]),
np.array([0.54296875, 0.26953125, 0.07421875]),
np.array([1, 0, 0]),
np.array([1.0, 0.078125, 0.57421875]),
np.array([0.1953125, 0.80078125, 0.1953125]),
]
# create the plot
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1, projection=ccrs.Robinson())
# add plot title
ax.set_title(
f"PAGES2k Network (n={len(pages2k_data)})")
# set the base map
# ----------------
ax.set_global()
# add coast lines
ax.coastlines()
# add land fratures using gray color
ax.add_feature(cfeature.LAND, facecolor="gray", alpha=0.3)
# add gridlines for latitude and longitude
ax.gridlines(edgecolor="gray", linestyle=":")
# plot the different archive types
# -------------------------------
# extract the name of the different archive types
archive_types = pages2k_data.archiveType.unique()
# plot the archive_type using a forloop
for i, type_i in enumerate(archive_types):
df = pages2k_data[pages2k_data["archiveType"] == type_i]
# count the number of appearances of the same archive_type
count = df["archiveType"].count()
# generate the plot
ax.scatter(
df["geo_meanLon"],
df["geo_meanLat"],
marker=markers[i],
color=colors[i],
edgecolor="k",
s=50,
transform=ccrs.Geodetic(),
label=f"{type_i} (n = {count})",
)
# add legend to the plot
ax.legend(
scatterpoints=1,
bbox_to_anchor=(0, -0.6),
loc="lower left",
ncol=2,
#fontsize=15,
)
<matplotlib.legend.Legend at 0x7f2724a37990>
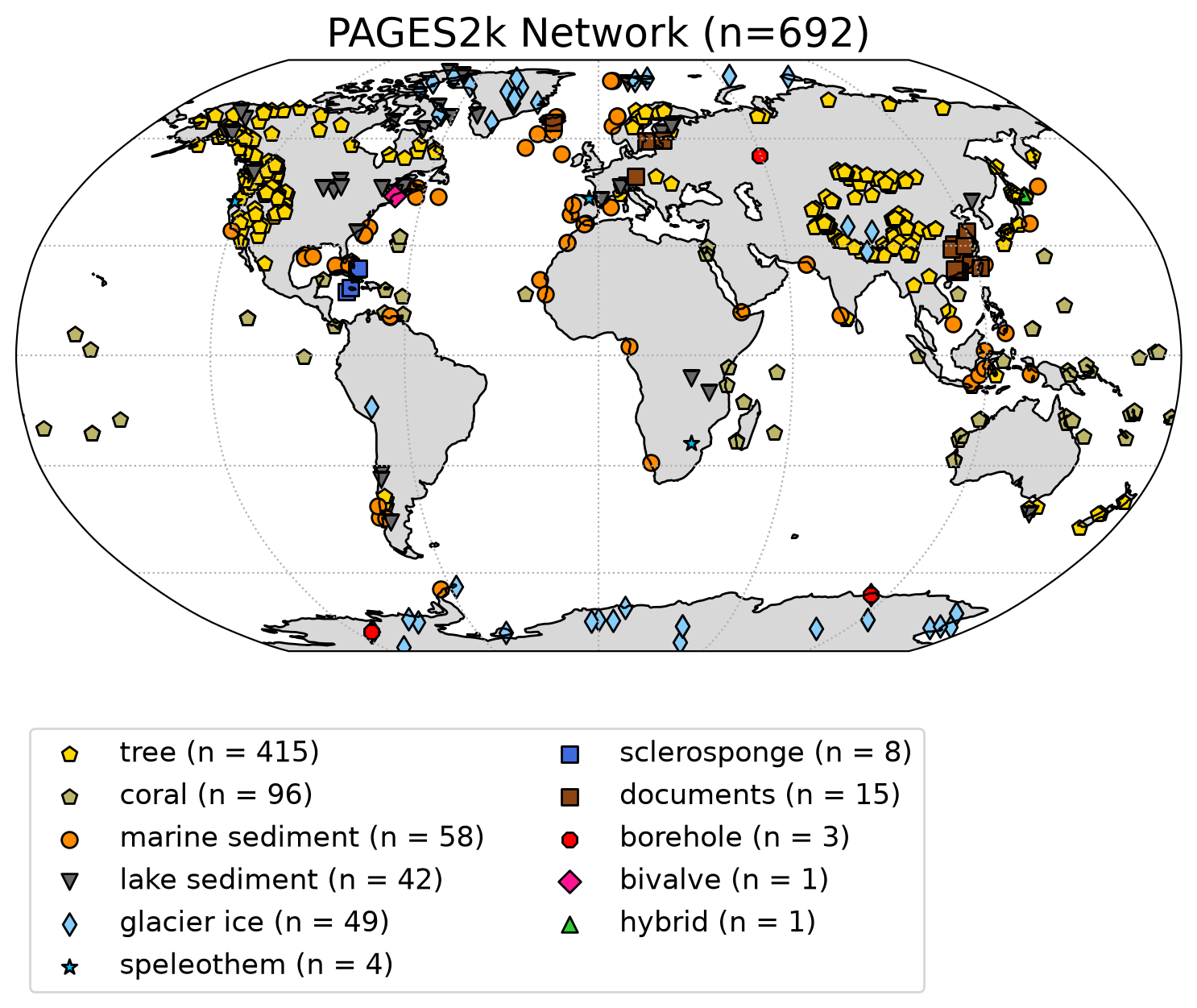
Questions 3#
You have just plotted the global distribution and temperature proxy type of the 692 records in the PAGES2k network!
Which temperature proxy is the most and least abundant in this database?
In what region do you observe the most and least temperature records? Why might this be the case?
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Questions_3")
Summary#
In this tutorial, you explored the PAGES2K network, which offers an extensive collection of proxy temperature reconstructions spanning the last 2,000 years. You surveyed various types of paleoclimate proxies and archives available, in addition to crafting a global map pinpointing the locations of the PAGES2k proxy records. As you advance throughout this module, you will extract and meticulously analyze the temperature timelines embedded within reconstructions such as those shown here.
Resources#
Code for this tutorial is based on existing notebooks from LinkedEarth that convert LiPD files to a Pandas dataframe and create a map of the PAGES2k network.
The following data is used in this tutorial:
PAGES2k Consortium. A global multiproxy database for temperature reconstructions of the Common Era. Sci Data 4, 170088 (2017). https://doi.org/10.1038/sdata.2017.88