![]()

Bonus Tutorial 8: Comparing Satellite Products With In Situ Data#
Week 1, Day 3, Remote Sensing
Content creators: Douglas Rao
Content reviewers: Katrina Dobson, Younkap Nina Duplex, Maria Gonzalez, Will Gregory, Nahid Hasan, Paul Heubel, Sherry Mi, Beatriz Cosenza Muralles, Jenna Pearson, Agustina Pesce, Chi Zhang, Ohad Zivan
Content editors: Paul Heubel, Jenna Pearson, Chi Zhang, Ohad Zivan
Production editors: Wesley Banfield, Paul Heubel, Jenna Pearson, Konstantine Tsafatinos, Chi Zhang, Ohad Zivan
Our 2024 Sponsors: CMIP, NFDI4Earth
Tutorial Objectives#
Estimated timing of tutorial: 25 minutes
In this bonus tutorial, our primary focus will be on the ‘Verification of Satellite Data’. Building on our previous modules where we explored various climate applications of satellite data, we will now delve into the critical task of assessing the quality and reliability of such data.
By the end of this tutorial, you will learn how to use land-based observations to validate satellite climate data. In this process, you will learn how to:
access the gridded climate data derived from station observations from AWS.
convert monthly total values to a daily rate.
correctly evaluate satellite data against land-based observations.
Setup#
# installations ( run this cell ONLY when using google colab or kaggle )
# !pip install s3fs --quiet
# # properly install cartopy in colab to avoid session crash
# !apt-get install libproj-dev proj-data proj-bin --quiet
# !apt-get install libgeos-dev --quiet
# !pip install cython --quiet
# !pip install cartopy --quiet
# !apt-get -qq install python-cartopy python3-cartopy --quiet
# !pip uninstall -y shapely --quiet
# !pip install shapely --no-binary shapely --quiet
# !pip install boto3 --quiet
# you may need to restart the runtime after running this cell and that is ok
# imports
import s3fs
import xarray as xr
import numpy as np
import matplotlib.pyplot as plt
import cartopy.crs as ccrs
import pooch
import os
import tempfile
import boto3
import botocore
from scipy import stats
Install and import feedback gadget#
Show code cell source
# @title Install and import feedback gadget
!pip3 install vibecheck datatops --quiet
from vibecheck import DatatopsContentReviewContainer
def content_review(notebook_section: str):
return DatatopsContentReviewContainer(
"", # No text prompt
notebook_section,
{
"url": "https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab",
"name": "comptools_4clim",
"user_key": "l5jpxuee",
},
).render()
feedback_prefix = "W1D3_T8"
Figure settings#
Show code cell source
# @title Figure settings
import ipywidgets as widgets # interactive display
%config InlineBackend.figure_format = 'retina'
plt.style.use(
"https://raw.githubusercontent.com/neuromatch/climate-course-content/main/cma.mplstyle"
)
Helper functions#
Show code cell source
# @title Helper functions
def pooch_load(filelocation=None, filename=None, processor=None):
shared_location = "/home/jovyan/shared/data/tutorials/W1D3_RemoteSensing" # this is different for each day
user_temp_cache = tempfile.gettempdir()
if os.path.exists(os.path.join(shared_location, filename)):
file = os.path.join(shared_location, filename)
else:
file = pooch.retrieve(
filelocation,
known_hash=None,
fname=os.path.join(user_temp_cache, filename),
processor=processor,
)
return file
Video 1: Verification of Satellite Data#
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Verification_Satellite_Data_Video")
If you want to download the slides: https://osf.io/download/w3r49/
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Verification_Satellite_Data_Slides")
Section 1: Evaluating Satellite Data with Observations#
Satellite data is frequently cross-verified against observations deemed reliable to evaluate its quality. Station-based observations and derived data are typically regarded as reliable references. When it comes to oceanic data, measurements taken by ships, buoys, drifters, or gliders are often used as a benchmark to assess the quality of satellite data.
In this tutorial, we will be using the nClimGrid dataset, a gridded climate dataset produced by NOAA. This dataset provides daily and monthly temperature and precipitation data, leveraging all available station observations. However, it’s important to note that this dataset is exclusive to the United States. We have selected this dataset due to its public availability on AWS. You are encouraged to explore other station data for the evaluation of satellite data in your projects.
Section 1.1: Accessing nClimGrid - a station-based gridded climate data#
The nClimGrid-monthly dataset is a gridded dataset derived from spatially interpolating data from the Global Historical Climatology Network (GHCN). The dataset includes monthly precipitation, monthly temperature average, monthly temperature maximum, and monthly temperature minimum. The dataset provides monthly values in an approximately \(5 \times 5\) km lat/lon grid for the Continental United States. Data is available from 1895 to the present via NOAA NCEI or AWS. We will be accessing the data via AWS directly.
# connect to the AWS S3 bucket for the nClimGrid Monthly Precipitation data
# read in the monthly precipitation data from nClimGrid on AWS
client = boto3.client(
"s3", config=botocore.client.Config(signature_version=botocore.UNSIGNED)
) # initialize aws s3 bucket client
file_nclimgrid = "noaa-nclimgrid-monthly-pds/nclimgrid_prcp.nc"
ds = xr.open_dataset(
pooch_load(
filelocation="http://s3.amazonaws.com/" + file_nclimgrid,
filename=file_nclimgrid,
)
)
ds
Downloading data from 'http://s3.amazonaws.com/noaa-nclimgrid-monthly-pds/nclimgrid_prcp.nc' to file '/tmp/noaa-nclimgrid-monthly-pds/nclimgrid_prcp.nc'.
SHA256 hash of downloaded file: d8040e4a98b62b1bd5ed1e5626a088d8a16f5e6c0c8d0a9ec633d48b4e12f065
Use this value as the 'known_hash' argument of 'pooch.retrieve' to ensure that the file hasn't changed if it is downloaded again in the future.
<xarray.Dataset> Size: 5GB
Dimensions: (time: 1577, lat: 596, lon: 1385)
Coordinates:
* time (time) datetime64[ns] 13kB 1895-01-01 1895-02-01 ... 2026-05-01
* lat (lat) float32 2kB 49.35 49.31 49.27 49.23 ... 24.65 24.6 24.56
* lon (lon) float32 6kB -124.7 -124.6 -124.6 ... -67.1 -67.06 -67.02
Data variables:
prcp (time, lat, lon) float32 5GB ...
Attributes: (12/14)
date_created: 2026-01-07 09:24:52.602657
date_modified: 2026-01-07 09:24:52.602763
Conventions: CF-1.6, ACDD-1.3
ncei_template_version: NCEI_NetCDF_Grid_Template_v2.0
title: nClimGrid
naming_authority: gov.noaa.ncei
... ...
geospatial_lat_min: 24.562532
geospatial_lat_max: 49.3542
geospatial_lon_min: -124.6875
geospatial_lon_max: -67.020836
geospatial_lat_units: degrees_north
geospatial_lon_units: degrees_eastThe nClimGrid dataset is available from 1895-01-01 until the present. Since our GPCP data is only available between 1979-01-01 and 2022-12-01, let’s extract only the data from that time period from the nClimGrid monthly data.
prcp_obs = ds.sel(time=slice("1979-01-01", "2022-12-31"))
prcp_obs
<xarray.Dataset> Size: 2GB
Dimensions: (time: 528, lat: 596, lon: 1385)
Coordinates:
* time (time) datetime64[ns] 4kB 1979-01-01 1979-02-01 ... 2022-12-01
* lat (lat) float32 2kB 49.35 49.31 49.27 49.23 ... 24.65 24.6 24.56
* lon (lon) float32 6kB -124.7 -124.6 -124.6 ... -67.1 -67.06 -67.02
Data variables:
prcp (time, lat, lon) float32 2GB ...
Attributes: (12/14)
date_created: 2026-01-07 09:24:52.602657
date_modified: 2026-01-07 09:24:52.602763
Conventions: CF-1.6, ACDD-1.3
ncei_template_version: NCEI_NetCDF_Grid_Template_v2.0
title: nClimGrid
naming_authority: gov.noaa.ncei
... ...
geospatial_lat_min: 24.562532
geospatial_lat_max: 49.3542
geospatial_lon_min: -124.6875
geospatial_lon_max: -67.020836
geospatial_lat_units: degrees_north
geospatial_lon_units: degrees_eastFrom the information about the precipitation data from the nClimGrid monthly dataset, we know it is the monthly total precipitation, which is the total amount of rainfall that a location receives for the entire month with the unit of millimeter.
prcp_obs.prcp
<xarray.DataArray 'prcp' (time: 528, lat: 596, lon: 1385)> Size: 2GB
[435842880 values with dtype=float32]
Coordinates:
* time (time) datetime64[ns] 4kB 1979-01-01 1979-02-01 ... 2022-12-01
* lat (lat) float32 2kB 49.35 49.31 49.27 49.23 ... 24.65 24.6 24.56
* lon (lon) float32 6kB -124.7 -124.6 -124.6 ... -67.1 -67.06 -67.02
Attributes:
references: GHCN-Monthly Version 3 (Vose et al. 2011), NCEI/NOAA, htt...
long_name: Precipitation, monthly total
standard_name: precipitation_amount
units: millimeter
valid_min: 0.0
valid_max: 2000.0However, the GPCP satellite precipitation variable is the daily precipitation rate with the unit of mm/day. This variable quantifies the average amount of precipitation in a day for a given location in a month.
To convert from the total amount to the precipitation rate, we just need to divide the amount by the number of days within a month (e.g., 31 days for January). We can use .days_in_month to achieve that.
# calculate precipitation rate from nClimGrid
obs_rate = prcp_obs.prcp / prcp_obs.time.dt.days_in_month
obs_rate
<xarray.DataArray (time: 528, lat: 596, lon: 1385)> Size: 3GB
array([[[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
...,
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan]],
[[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
...,
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan]],
[[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
...,
...
...,
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan]],
[[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
...,
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan]],
[[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
...,
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan]]])
Coordinates:
* time (time) datetime64[ns] 4kB 1979-01-01 1979-02-01 ... 2022-12-01
* lat (lat) float32 2kB 49.35 49.31 49.27 49.23 ... 24.65 24.6 24.56
* lon (lon) float32 6kB -124.7 -124.6 -124.6 ... -67.1 -67.06 -67.02# generate the map of precipitation rate from nClimGrid monthly data
obs_rate[0].plot()
<matplotlib.collections.QuadMesh at 0x7f09d73dbcd0>
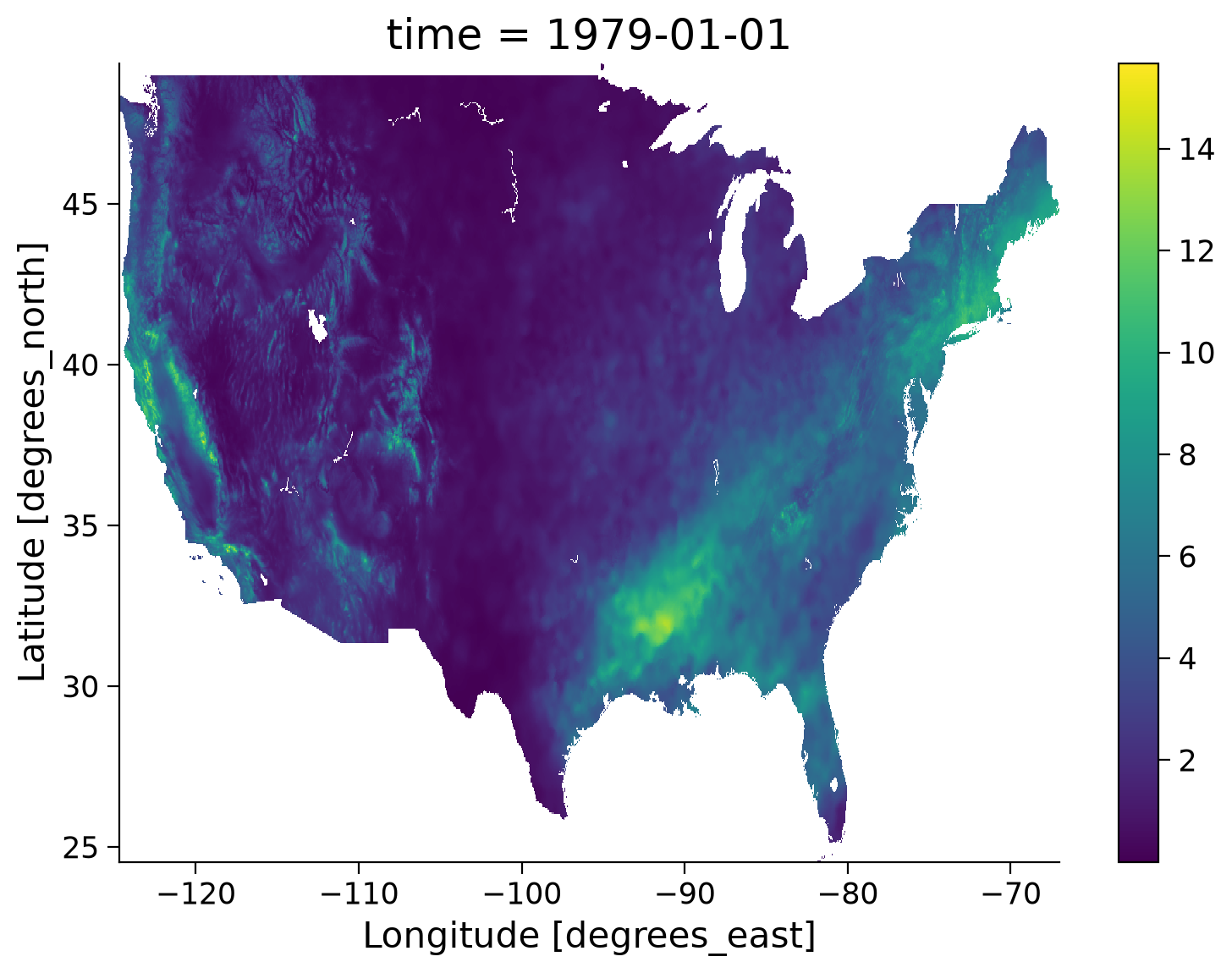
In this quick map, we can see the value range of the precipitation rate appears to be reasonable compared to the GPCP monthly precipitation CDR data (0-20 mm/day).
Section 1.2: Read GPCP Monthly Precipitation Data#
Now we are ready to compare our land-based observations to the monthly GPCP satellite from AWS public data catalog.
# get the list of all data files in the AWS S3 bucket
fs = s3fs.S3FileSystem(anon=True)
file_pattern = "noaa-cdr-precip-gpcp-monthly-pds/data/*/gpcp_v02r03_monthly_*.nc"
file_location = fs.glob(file_pattern)
# open connection to all data files
file_ob = [
pooch_load(filelocation="http://s3.amazonaws.com/" + file, filename=file)
for file in file_location
]
# open all the monthly data files and concatenate them along the time dimension.
# this process will take ~ 1 minute to complete due to the number of data files.
ds_gpcp = xr.open_mfdataset(file_ob, combine="nested", concat_dim="time")
# comment for colab users only: this could toss an error message for you.
# you should still be able to use the dataset with this error just not print ds
# you can try uncommenting the following line to avoid the error
# ds_gpcp.attrs['history']='' # the history attribute have unique chars that cause a crash on Google colab.
ds_gpcp
<xarray.Dataset> Size: 48MB
Dimensions: (latitude: 72, longitude: 144, time: 567, nv: 2)
Coordinates:
* latitude (latitude) float32 288B -88.75 -86.25 -83.75 ... 86.25 88.75
* longitude (longitude) float32 576B 1.25 3.75 6.25 ... 353.8 356.2 358.8
* time (time) datetime64[ns] 5kB 1979-01-01 1979-02-01 ... 2026-03-01
Dimensions without coordinates: nv
Data variables:
lat_bounds (time, latitude, nv) float32 327kB dask.array<chunksize=(1, 72, 2), meta=np.ndarray>
lon_bounds (time, longitude, nv) float32 653kB dask.array<chunksize=(1, 144, 2), meta=np.ndarray>
time_bounds (time, nv) datetime64[ns] 9kB dask.array<chunksize=(1, 2), meta=np.ndarray>
precip (time, latitude, longitude) float32 24MB dask.array<chunksize=(1, 72, 144), meta=np.ndarray>
precip_error (time, latitude, longitude) float32 24MB dask.array<chunksize=(1, 72, 144), meta=np.ndarray>
Attributes: (12/45)
Conventions: CF-1.6, ACDD 1.3
title: Global Precipitation Climatatology Project (G...
source: oc.197901.sg
references: Huffman et al. 1997, http://dx.doi.org/10.117...
history: 1) �R
`�, Dr. Jian-Jian Wang, U of Maryland,...
Metadata_Conventions: CF-1.6, Unidata Dataset Discovery v1.0, NOAA ...
... ...
metadata_link: gov.noaa.ncdc:C00979
product_version: v23rB1
platform: NOAA POES (Polar Orbiting Environmental Satel...
sensor: AVHRR>Advanced Very High Resolution Radiometer
spatial_resolution: 2.5 degree
comment: Processing computer: eagle2.umd.edu# get the GPCP precipitation rate
prcp_sat = ds_gpcp.precip
prcp_sat
<xarray.DataArray 'precip' (time: 567, latitude: 72, longitude: 144)> Size: 24MB
dask.array<concatenate, shape=(567, 72, 144), dtype=float32, chunksize=(1, 72, 144), chunktype=numpy.ndarray>
Coordinates:
* latitude (latitude) float32 288B -88.75 -86.25 -83.75 ... 86.25 88.75
* longitude (longitude) float32 576B 1.25 3.75 6.25 ... 353.8 356.2 358.8
* time (time) datetime64[ns] 5kB 1979-01-01 1979-02-01 ... 2026-03-01
Attributes:
long_name: NOAA Climate Data Record (CDR) of GPCP Monthly Satellite-...
standard_name: precipitation amount
units: mm/day
valid_range: [ 0. 100.]
cell_methods: area: mean time: meanSection 1.3: Spatial Pattern#
Now, let’s take a quick look at the spatial pattern between these two datasets for a selected month (e.g., 1979-01-01).
# set up the geographical region for continental US
central_lat = 37.5
central_lon = -96
extent = [-120, -70, 21, 50]
central_lon = np.mean(extent[:2])
central_lat = np.mean(extent[2:])
# extract sat and obs data for the month of 1979-01-01
sat = prcp_sat.sel(time="1979-01-01")
obs = obs_rate.sel(time="1979-01-01")
# initiate plot for North America using two suplots
fig, axs = plt.subplots(
2,
subplot_kw={"projection": ccrs.AlbersEqualArea(central_lon, central_lat)},
figsize=(9, 12),
sharex=True,
sharey=True,
)
axs[0].set_extent(extent)
axs[0].coastlines()
axs[0].set_title("GPCP Monthly")
sat.plot(
ax=axs[0],
transform=ccrs.PlateCarree(),
vmin=0,
vmax=15,
cbar_kwargs=dict(shrink=0.5, label="GPCP Precipitation (mm/day)"),
)
axs[1].set_extent(extent)
axs[1].coastlines()
axs[1].set_title("nClimGrid Monthly")
obs.plot(
ax=axs[1],
transform=ccrs.PlateCarree(),
vmin=0,
vmax=15,
cbar_kwargs=dict(shrink=0.5, label="nClimGrid Precipitation (mm/day)"),
)
<cartopy.mpl.geocollection.GeoQuadMesh at 0x7f09ce9e4990>
/home/runner/micromamba/envs/climatematch/lib/python3.11/site-packages/cartopy/io/__init__.py:242: DownloadWarning: Downloading: https://naturalearth.s3.amazonaws.com/50m_physical/ne_50m_coastline.zip
warnings.warn(f'Downloading: {url}', DownloadWarning)
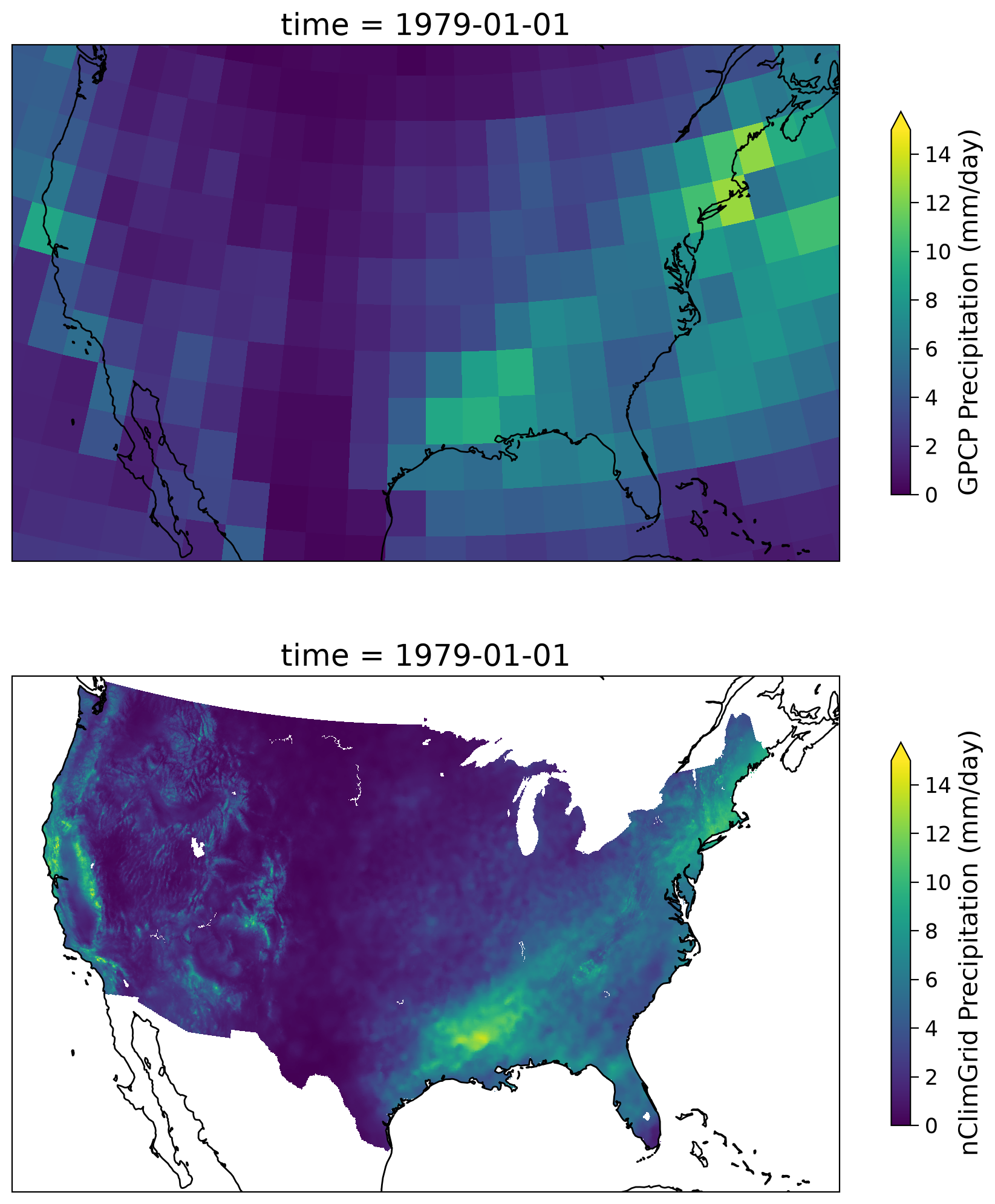
Overall, we have a similar spatial pattern but with widely different spatial resolution (i.e., 5km v.s. 2.5°).
Section 1.4: Time Series Comparison#
Let’s use New York City as an example, we can examine the time series of the satellite and observation-based dataset to evaluate the performance.
The latitute and longitute of NYC is (40.71°N, 74.01°W). We will use it to extract the time series from GPCP and nClimGrid using the nearest method you discussed in Day 1 due to the differing resolutions of each dataset.
# note that GPCP data is stored as 0-360 degree for the longitude, so the longitude should be using (360 - lon)
sat = prcp_sat.sel(longitude=285.99, latitude=40.71, method="nearest")
obs = obs_rate.sel(lon=-74.01, lat=40.71, method="nearest") # precipitation rate
obs_total = prcp_obs.sel(lon=-74.01, lat=40.71, method="nearest") # total amount
# let's look at the comparison between the precipitation rate from nClimGrid and satellite CDR
fig, ax = plt.subplots()
obs.plot(label="nClimGrid Monthly Precipitation Rate", ax=ax)
sat.plot(color="k", alpha=0.6, label="GPCP Monthly Precipitation Rate", ax=ax)
ax.set_ylabel("nClimGrid v.s. GPCP (New York City) (mm/day)")
ax.legend()
<matplotlib.legend.Legend at 0x7f09d42eb550>
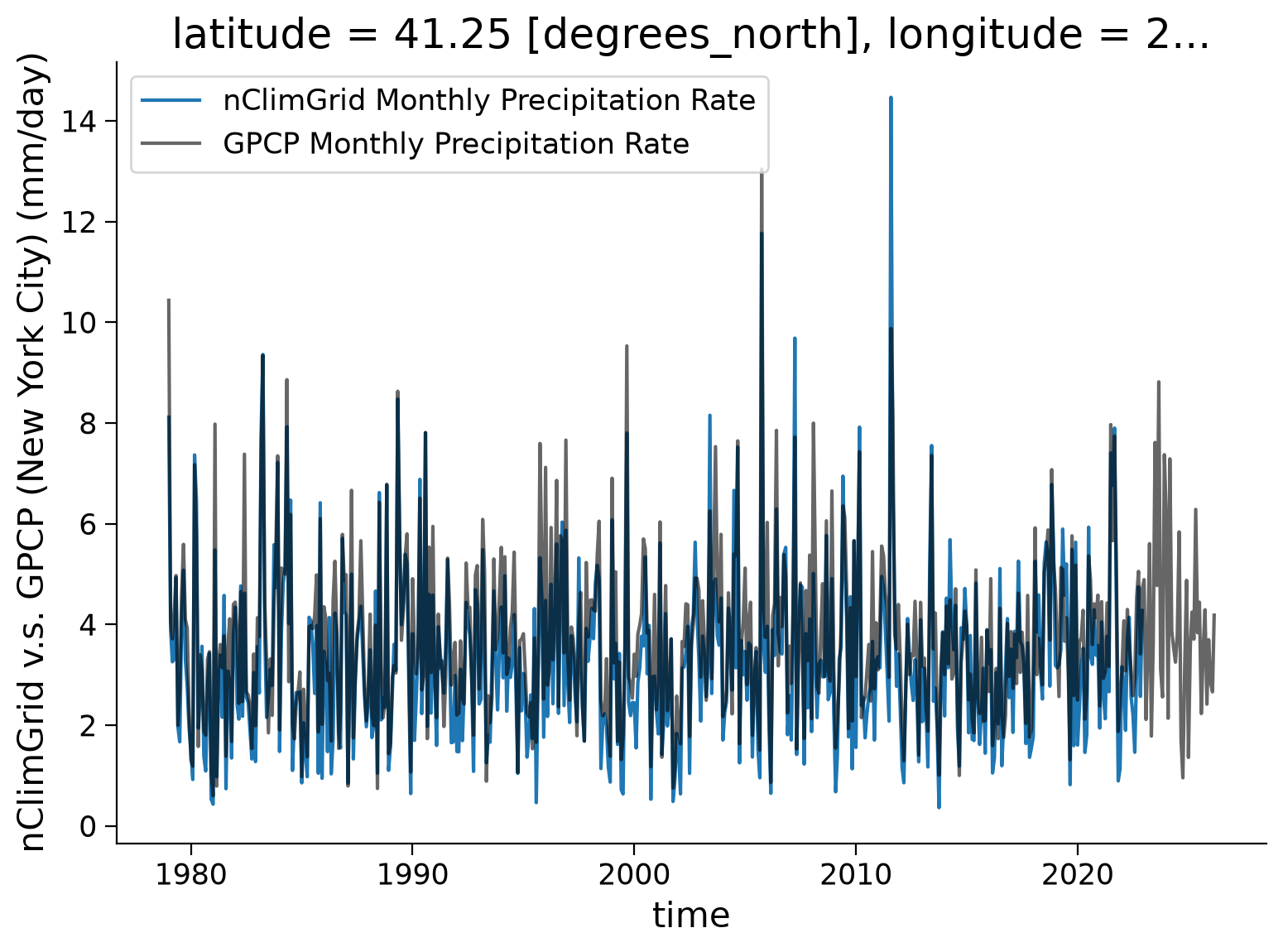
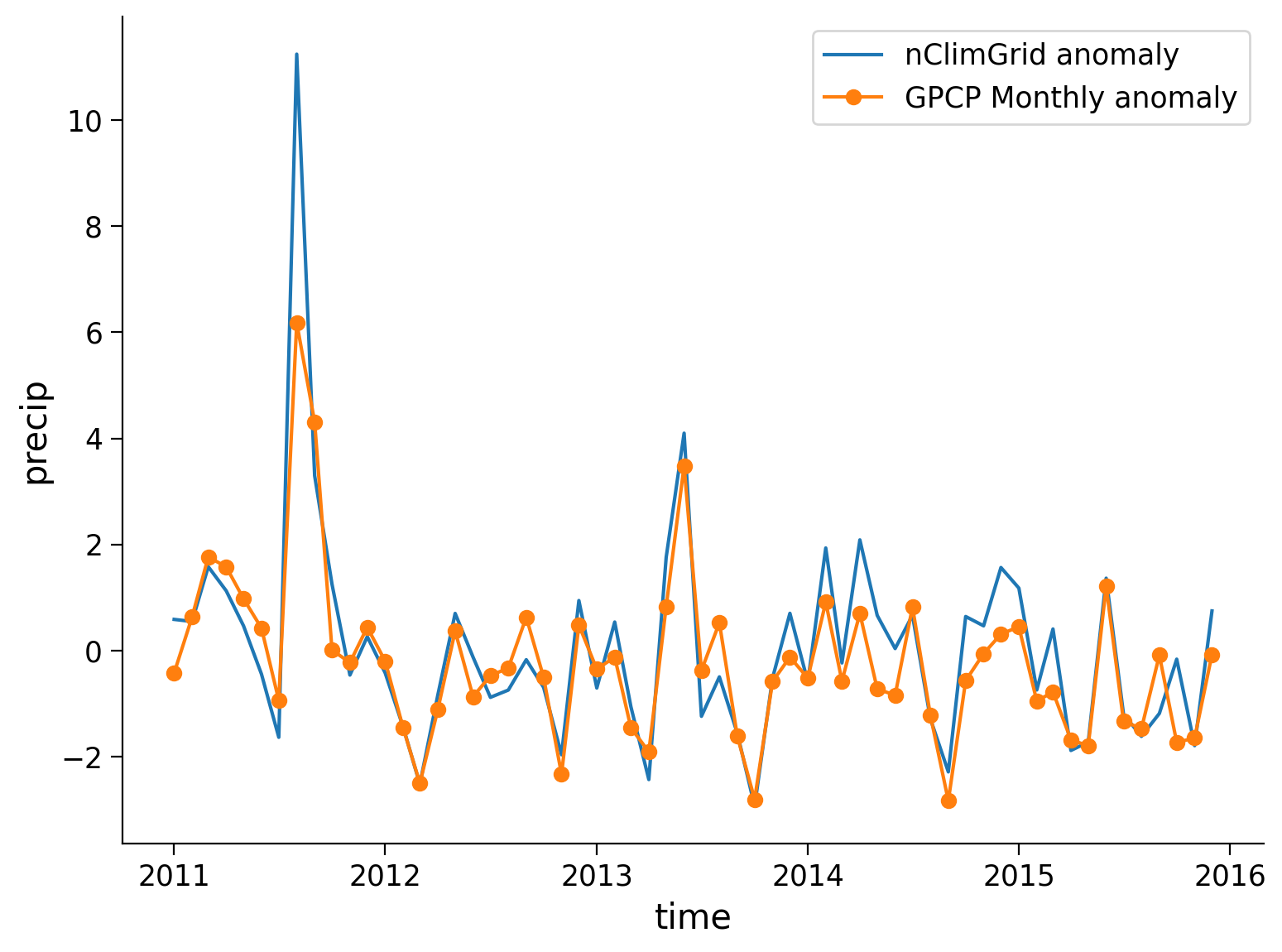
Now we are going to zoom in to a few years to see how the data compares.
fig, ax = plt.subplots()
# select 2011 to 2015 slice
obs.sel(time=slice("2011-01-01", "2015-12-01")).plot(label="nClimGrid", ax=ax)
sat.sel(time=slice("2011-01-01", "2015-12-01")).plot(marker="o", label="GPCP Monthly", ax=ax)
# aesthetics
ax.set_xlabel("Time (months)")
ax.set_ylabel("Precipitation (mm/day)")
ax.set_title("New York City – 2011-2015")
ax.legend()
<matplotlib.legend.Legend at 0x7f09d7422f10>
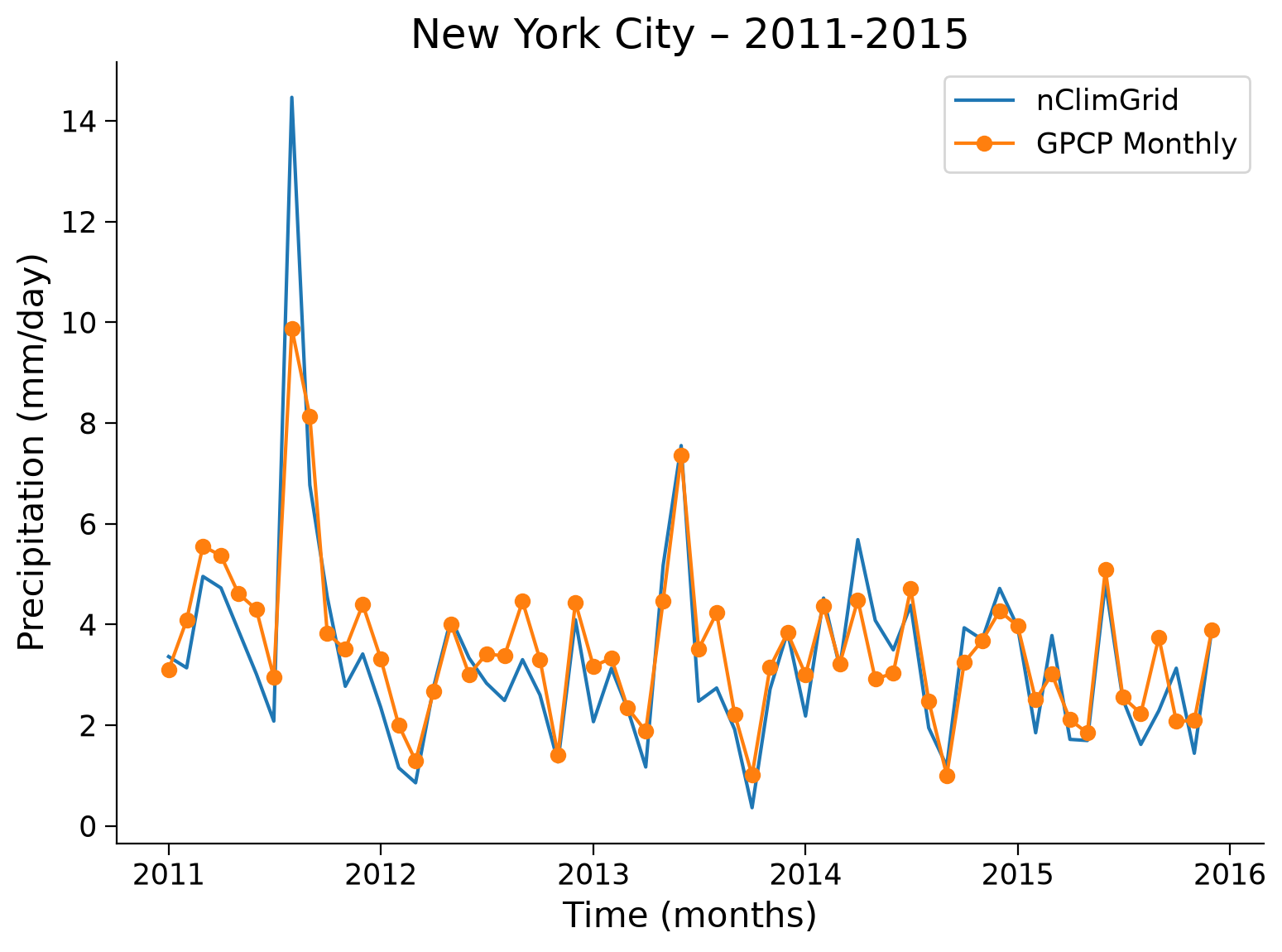
We see a great alignment in the precipitation rate between the nClimGrid and GPCP data when we look at the details over this small chosen window. However, we cannot zoom in to every location for all times to confirm they are a good match. We can use statistics to quantify the relationship between these two datasets for as in a automated fashion, and will do so in the next section.
Section 1.5: Quantify the Difference#
One way to more robustly compare the datasets is through a scatterplot. The data would ideally follow the 1:1 line, which would suggest that they are very closely matched. Let’s make this plot and observe how our data compares to one another:
# make sure that both observation and satellite data are for the samte time period
sat = sat.sel(time=slice("1979-01-01", "2022-12-01"))
obs = obs.sel(time=slice("1979-01-01", "2022-12-01"))
# plot the scatter plot between nClimGrid and GPCP monthly precipitation CDR
fig, ax = plt.subplots()
fig.suptitle("GPCP Precipitation v.s. nClimGrid")
# scatter data
ax.scatter(sat, obs, alpha=0.6)
# aesthetics
y_lim = (0, 15)
x_lim = (0, 15)
ax.plot((0, 15), (0, 15), "r-") # Add 1:1 line
ax.set_ylim(y_lim)
ax.set_xlim(x_lim)
ax.set_xlabel("GPCP Precipitation (mm/day)")
ax.set_ylabel("nClimGrid (mm/day)")
Text(0, 0.5, 'nClimGrid (mm/day)')
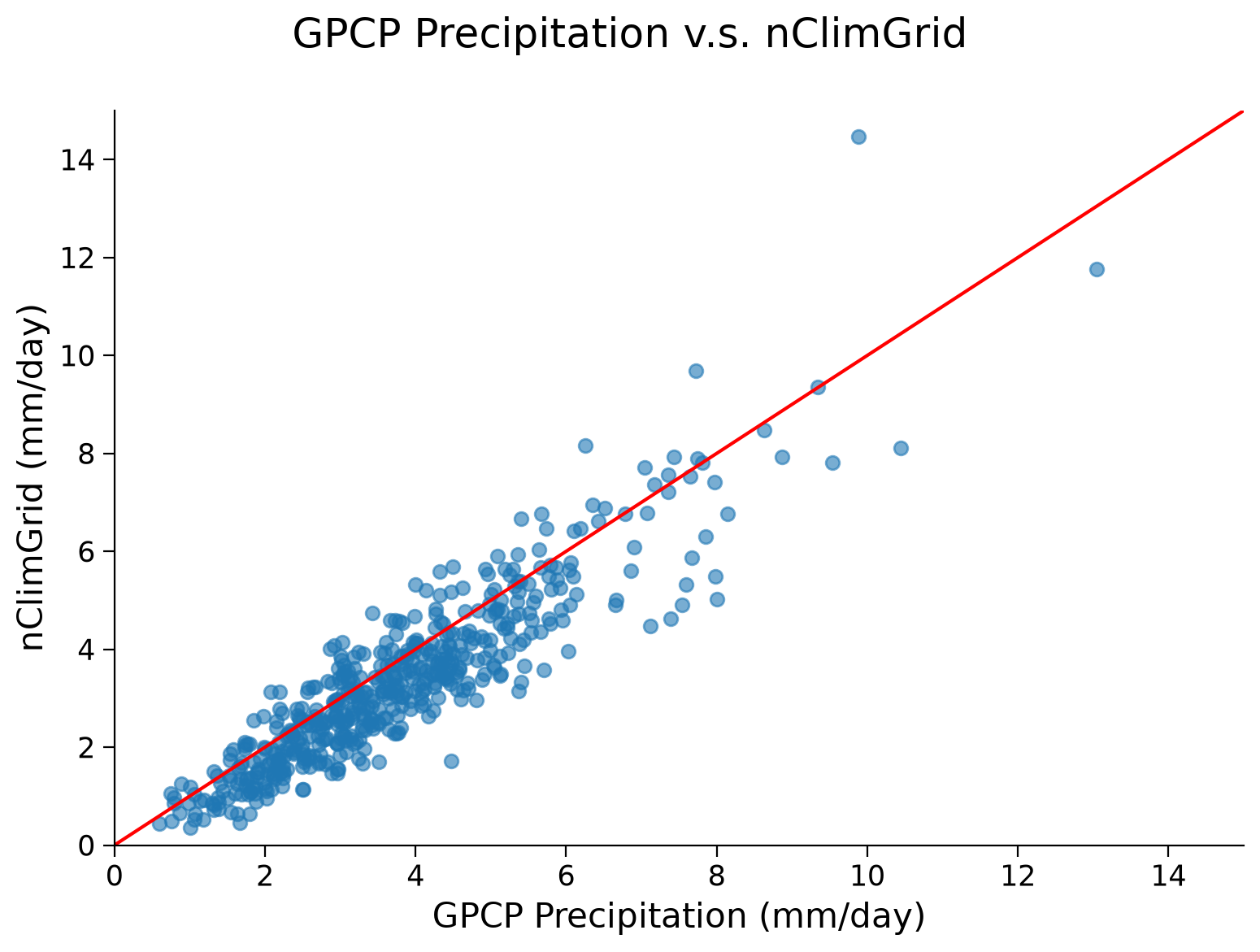
By eye, there appears to be a stong correlation between the satellite data and the observations for NYC, with much of the data following the 1:1 line plotted in red. As in the last tutorial, we can calculate the correlation coefficient and corresponding p-value.
r, p = stats.pearsonr(sat, obs)
print("Corr Coef: " + str(r) + ", p-val: " + str(p))
Corr Coef: 0.9071569149331666, p-val: 6.968622511262489e-200
Coding Exercises 1.5#
Sometimes, we are more interested in the difference among the anomaly data rather than the total data. Using the same location, compare the anomaly data.
# calculate climatology for the 1981-2010 period for both GPCP and nClimGrid
sat_clim = ...
obs_clim = ...
# calculate anomaly of the NYC time series for both GPCP and nClimGrid
sat_clim_anom = ...
obs_clim_anom = ...
# plot time series and scatter plot between two time series
fig, ax = plt.subplots()
# obs_clim_anom.sel(time=slice("2011-01-01", "2015-12-01")).plot(
# label="nClimGrid anomaly", ax=ax
# )
# sat_clim_anom.sel(time=slice("2011-01-01", "2015-12-01")).plot(
# marker="o", label="GPCP Monthly anomaly", ax=ax
# )
ax.legend()
# plot the scatter plot between nClimGrid and GPCP monthly precipitation CDR
fig, ax = plt.subplots()
fig.suptitle("GPCP Precipitaion v.s. nClimGrid")
# ax.scatter(sat_clim_anom, obs_clim_anom, alpha=0.6)
# Add 1:1 line
y_lim = (0, 15)
x_lim = (0, 15)
ax.plot((0, 15), (0, 15), "r-")
ax.set_ylim(y_lim)
ax.set_xlim(x_lim)
ax.set_xlabel("GPCP Precipitation anomaly (mm/day)")
ax.set_ylabel("nClimGrid anomaly (mm/day)")
# calculate and print correlation coefficient and p-value
# r, p = ...
# print("Corr Coef: " + str(r) + ", p-val: " + str(p))
/tmp/ipykernel_7319/1854925119.py:17: UserWarning: No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
ax.legend()
Text(0, 0.5, 'nClimGrid anomaly (mm/day)')
Example output:

Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Coding_Exercise_1_5")
Summary#
In this tutorial, you explored how to use station-based observations within the U.S. to evaluate satellite precipitation data. While this isn’t a global comparison, the methodology can be applied to other station or observation data you may wish to utilize.
When carrying out these comparisons, remember the following key points:
Ensure that both the satellite data and the observations represent the same quantity (for example, total precipitation amount versus precipitation rate).
Comparisons should be made for the same geolocation (or very near to it) and the same time period.
Be aware of potential spatial scale effects. Satellite data measures over a large area, whereas observations may be narrowly focused, particularly for elements that exhibit substantial spatial variability. This can lead to considerable uncertainty in the satellite data.